I have data in a txt file in a format that looks like this.
ScanHeader # 1
position = 1, start_mass= 2.000000, end_mass = 535.010058
start_time = 0.034048, end_time = 0.000000, packet_type = 24
num_readings = 114, integ_intens = 14276257.301926, data packet pos = 1026
uScanCount = 0, PeakIntensity = 6799450.500000, PeakMass = 18.045876
Scan Segment = 0, Scan Event = 0
Precursor Mass
Collision Energy
Isolation width
Polarity positive, Cenrtoid Data, Full Scan Type, MS Scan
SourceFragmentation Any, Type Ramp, Values = 0, Mass Ranges = 0
Turbo Scan Any, IonizationMode ElectronImpact, Corona Any
Detector Any, Value = 0.00, ScanTypeIndex = -1
DataPeaks
Packet # 0, intensity = 3691.226074, mass/position = 2.112536
saturated = 0, fragmented = 0, merged = 0
Packet # 1, intensity = 42881.203125, mass/position = 3.466080
saturated = 0, fragmented = 0, merged = 0
Packet # 2, intensity = 3006256.000000, mass/position = 4.184193
saturated = 0, fragmented = 0, merged = 0
Ideally, the output should be a csv file that looks like this:
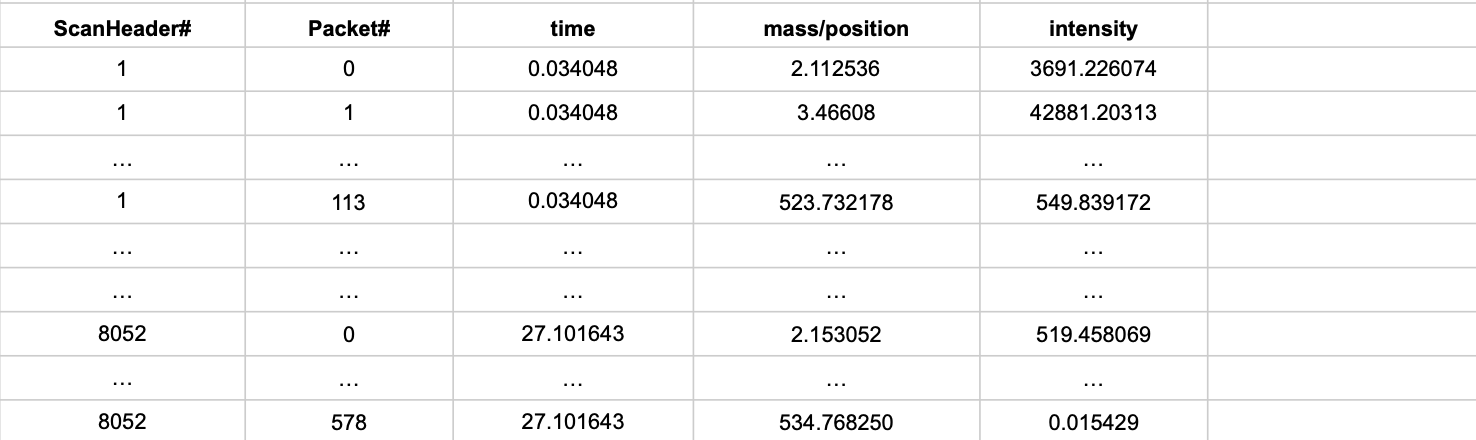
I have tried using regex, as well as the read_csv option, but none seem to give me the desired output. The closest I've gotten is with regex, where I managed to extract all the data I needed but I had trouble putting it into the dataframe. The code looks like this:
from tabulate import tabulate
import re
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data = re.findall(r'\d*last_scan = \d*\d.\d*', newfile.read())
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data1 = re.findall(r'\d* start_time = \d*\d.\d*', newfile.read())
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data2 = re.findall(r'\d* end_time = \d*\d.\d*', newfile.read())
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data3 = re.findall(r'\d*low_mass = \d*\d.\d*', newfile.read())
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data4 = re.findall(r'\d*high_mass = \d*\d.\d*', newfile.read())
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data5 = re.findall(r'\d*ScanHeader # \d', newfile.read())
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data6 = re.findall(r'\d*Packet # \d*', newfile.read())
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data7 = re.findall(r'\d* intensity = \d*\d.\d*', newfile.read())
with open('2020-06-23-Didecylamine-deriv-0,1uL.txt') as newfile:
data8 = re.findall(r'\d* mass/position = \d*\d.\d*', newfile.read())
import pandas as pd
data = {'Scanheader': [data5],
'Packet Number': [data6],
'Intensity': [data7],
'Mass/Position': [data8]
}
df = pd.DataFrame(data)
df.to_csv('2020-06-23-Didecylamine-deriv-0,1uL.csv', index=False)
The output I am getting with this code looks like this:

I am aware that there are ways to make this code way less complicated, but I'm still a beginner and haven't found any ways to make it simpler that work. Any tips will be greatly appreciated :)
CodePudding user response:
You should open your file only once.
You can first match the whole text for all ScanHeaders using re flags re.MULTILINE re.DOTALL.
Iterate over these matches and extract Header # and time.
Finally iterate over the packets (found in the previous match) to extract the other columns:
data = []
scanHeader_pattern = re.compile(r'ScanHeader.*?(?=ScanHeader|\Z)', flags= re.MULTILINE re.DOTALL)
packet_pattern = re.compile(r'Packet.*?(?=Packet|\Z)', flags= re.MULTILINE re.DOTALL)
header_nb_pattern = re.compile(r'ScanHeader # (\d )')
time_pattern = re.compile(r'start_time = (\d \.\d )', re.MULTILINE)
packet_nb_pattern = re.compile(r'Packet # (\d )')
intensity_pattern = re.compile(r'intensity = (\d \.\d )')
mass_pos_pattern = re.compile(r'mass/position = (\d \.\d )')
for sh in re.findall(scanHeader_pattern, newfile.read()):
h_nb = int(re.search(header_nb_pattern, sh).group(1))
t = float(re.search(time_pattern, sh).group(1))
for p in re.findall(packet_pattern, sh):
p_nb = int(re.search(packet_nb_pattern, p).group(1))
intensity = float(re.search(intensity_pattern, p).group(1))
mass_pos = float(re.search(mass_pos_pattern, p).group(1))
data.append(
{'Scanheader': h_nb,
'Packet Number': p_nb,
'Time': t,
'Intensity': intensity,
'Mass/Position': mass_pos
}
)
df = pd.DataFrame(data)