I am new in Python and I am struggling to reshape my dataFrame.
Here attached is a sample of the data I have.
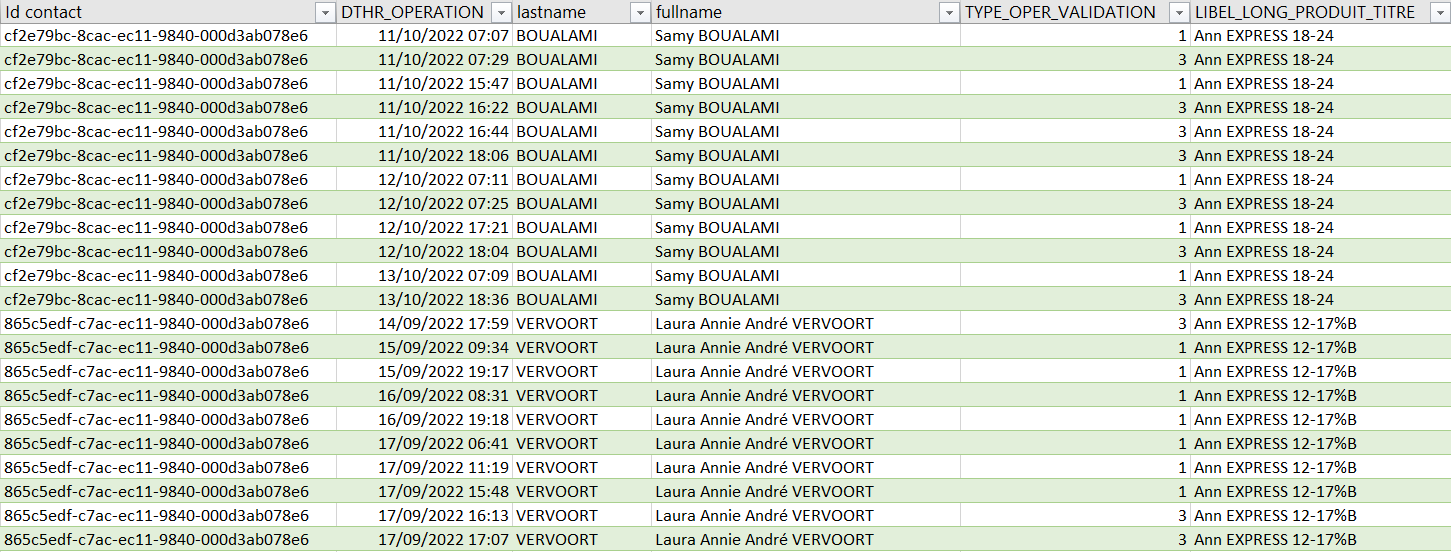
For a particular client (contact_id), I want to add an new date column that actually substracts the DTHR_OPERATION date for a 'TYPE_OPER_VALIDATION = 3' minus the DTHR_OPERATION date for a 'TYPE_OPER_VALIDATION = 1'.
If the 'TYPE_OPER_VALIDATION' is equal to 3 and that there is less than a hour difference between those two dates, I want to add a string such as 'connection' for example in the new column.
I have an issue "python Series' object has no attribute 'total_seconds" when I try to compare if the time difference is indeed minus or equal to an hour. I tried many solutions I found on Internet but I always seem to have a data type issue.
Here is my code snippet:
df_oper_one = merged_table.loc[(merged_table['TYPE_OPER_VALIDATION']==1),['contact_id','TYPE_OPER_VALIDATION','DTHR_OPERATION']]
df_oper_three = merged_table.loc[(merged_table['TYPE_OPER_VALIDATION']==3),['contact_id','TYPE_OPER_VALIDATION','DTHR_OPERATION']]
connection = []
for row in merged_table['contact_id']:
if (df_validation.loc[(df_validation['TYPE_OPER_VALIDATION']==3)]) & ((pd.to_datetime(df_oper_three['DTHR_OPERATION'],format='%Y-%m-%d %H:%M:%S') - pd.to_datetime(df_oper_one['DTHR_OPERATION'],format='%Y-%m-%d %H:%M:%S').total_seconds()) <= 3600): connection.append('connection')
# if diff_date.total_seconds() <= 3600: connection.append('connection')
else: connection.append('null')
merged_table['connection'] = pd.Series(connection)
CodePudding user response:
Hello Nicolas and welcome to Stack Overflow. Please remember to always include sample data to reproduce your issue. Here is sample data to reproduce part of your dataframe:
df = pd.DataFrame({'Id contact':['cf2e79bc-8cac-ec11-9840-000d3ab078e6']*12 ['865c5edf-c7ac-ec11-9840-000d3ab078e6']*10,
'DTHR OPERATION':['11/10/2022 07:07', '11/10/2022 07:29', '11/10/2022 15:47', '11/10/2022 16:22', '11/10/2022 16:44', '11/10/2022 18:06', '12/10/2022 07:11', '12/10/2022 07:25', '12/10/2022 17:21', '12/10/2022 18:04', '13/10/2022 07:09', '13/10/2022 18:36', '14/09/2022 17:59', '15/09/2022 09:34', '15/09/2022 19:17', '16/09/2022 08:31', '16/09/2022 19:18', '17/09/2022 06:41', '17/09/2022 11:19', '17/09/2022 15:48', '17/09/2022 16:13', '17/09/2022 17:07'],
'lastname':['BOUALAMI']*12 ['VERVOORT']*10,
'TYPE_OPER_VALIDATION':[1, 3, 1, 3, 3, 3, 1, 3, 1, 3, 1, 3, 3, 1, 1, 1, 1, 1, 1, 1, 3, 3]})
df['DTHR OPERATION'] = pd.to_datetime(df['DTHR OPERATION'])
I would recommend creating a new table to more easily accomplish your task:
df2 = pd.merge(df[['Id contact', 'DTHR OPERATION']][df['TYPE_OPER_VALIDATION']==3], df[['Id contact', 'DTHR OPERATION']][df['TYPE_OPER_VALIDATION']==1], on='Id contact', suffixes=('_type3','_type1'))
Then find the time difference:
df2['seconds'] = (df2['DTHR OPERATION_type3']-df2['DTHR OPERATION_type1']).dt.total_seconds()
Finally, flag connections of an hour or less:
df2['connection'] = np.where(df2['seconds']<=3600, 'yes', 'no')
Hope this helps!
CodePudding user response:
Thanks to your help I know have a df3['first_connection'] column that correctly flag them.
preview df3['first_connection']
![preview df3['first_connection']](https://i.stack.imgur.com/H1MfF.png){kind=link}
Here is a preview of the result and the code snippet is just below :
df2 = df_support.merge(df_contact, left_on='bd_linkedcustomer', right_on='contact_id').merge(df_validation, left_on='bd_supportserialnumber',right_on='NUM_SERIE_SUPPORT')
df3 = pd.merge(df2[['contact_id', 'DTHR_OPERATION']][df2['TYPE_OPER_VALIDATION']==3], df2[['contact_id', 'DTHR_OPERATION']][df2['TYPE_OPER_VALIDATION']==1], on='contact_id', suffixes=('_type3','_type1'))
df3['seconds'] = (df3['DTHR_OPERATION_type3']-df3['DTHR_OPERATION_type1']).dt.total_seconds()
df3['first_connection'] = np.where((df3['seconds']<=3600) & (df3['seconds']>0), 'yes', 'no')
I repeated the process in a df4 where I wanted to flag the time difference where df2['TYPE_OPER_VALIDATION']==3 - df2['TYPE_OPER_VALIDATION']==3 to spot the second or more connection
Here is a preview of the result and the code snippet is just below :
preview df4['second_or_more_connection']
![preview df4['second_or_more_connection']](https://i.stack.imgur.com/Vxel8.png){kind=link}
df4 = pd.merge(df2[['contact_id', 'DTHR_OPERATION']][df2['TYPE_OPER_VALIDATION']==3], df2[['contact_id', 'DTHR_OPERATION']][df2['TYPE_OPER_VALIDATION']==3], on='contact_id', suffixes=('_type3','_type3bis'))
df4['seconds_type3'] = (df4['DTHR_OPERATION_type3']-df4['DTHR_OPERATION_type3bis']).dt.total_seconds()
df4['second_or_more_connection'] = np.where((df4['seconds_type3']<=3600) & (df4['seconds_type3']>0), 'yes', 'no')
The thing is I now want to have a final connection column that paste the 'yes' value from the df3['first_connection'] column labeled as '1st connection', the 'yes' value from the df4['second_or_more_connection'] labeled as '2nd or more connection', the 1 value from the df2['TYPE_OPER_VALIDATION'] labeled as '1st journey' and the remaining empty value labeled as 'null'.
I struggle to do so as I am dealing with three different dataframes. I tried some nested for loops, some concatenation and so on but I don't know which option I should go for since I don't have expected results.
Also I end up having way too many values, I want to do an inner join at the end to only have the date field (df2[DTHR_OPERATION]) occuring once.
Can you help me out or guide me to do such data manipulation and transformation pls ? Many thanks for your support :)