I have been wrestling with this for a day or two now, and I can't seem to get it right.
project_index = [
{A: ['1', '2', '3']},
{B: ['4', '5', '6']},
{C: ['7', '8', '9']},
{D: ['10', '11', '12']},
{E: ['13', '14', '15']},
{F: ['16', '17', '18']}
]
I have tried so many different things to try to get this into a .CSV table, but it keeps coming out in ridiculously incorrect format, eg them tiling down diagonally, or a bunch of rows of just the keys over and over (EG:
A B C D E F
A B C D E F
A B C D E F
A B C D E F )
Also, even if I get the values to show up, the entire array of strings shows up in one cell.
Is there any way I can get it to make each dictionary a column, with each string in the array value as its own cell in said column?
Example:
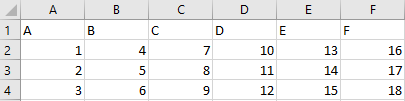
Thank you in advance!
CodePudding user response:
Assuming all your keys are unique... then this (Modified Slightly):
project_index = [
{'A': ['1', '2', '3']},
{'B': ['4', '5', '6']},
{'C': ['7', '8', '9']},
{'D': ['10', '11', '12', '20']},
{'E': ['13', '14', '15']},
{'F': ['16', '17', '18']}
]
Should probably look like this:
project_index_dict = {}
for x in project_index:
project_index_dict.update(x)
print(project_index_dict)
# Output:
{'A': ['1', '2', '3'],
'B': ['4', '5', '6'],
'C': ['7', '8', '9'],
'D': ['10', '11', '12', '20'],
'E': ['13', '14', '15'],
'F': ['16', '17', '18']}
At this point, rather than re-invent the wheel... you could just use pandas.
import pandas as pd
# Work-around for uneven lengths:
df = pd.DataFrame.from_dict(project_index_dict, 'index').T.fillna('')
df.to_csv('file.csv', index=False)
Output file.csv:
A,B,C,D,E,F
1,4,7,10,13,16
2,5,8,11,14,17
3,6,9,12,15,18
,,,20,,
csv module method:
import csv
from itertools import zip_longest, chain
header = []
for d in project_index:
header.extend(list(d))
project_index_rows = [dict(zip(header, x)) for x in
zip_longest(*chain(list(*p.values())
for p in project_index),
fillvalue='')]
with open('file.csv', 'w') as f:
writer = csv.DictWriter(f, fieldnames = header)
writer.writeheader()
writer.writerows(project_index_rows)
CodePudding user response:
My solution does not use Pandas. Here is the plan:
- For the header row, grab all the keys from the dictionaries
- For the data row, use
zipto transpose columns -> rows
import csv
def first_key(d):
"""Return the first key in a dictionary."""
return next(iter(d))
def first_value(d):
"""Return the first value in a dictionary."""
return next(iter(d.values()))
with open("output.csv", "w", encoding="utf-8") as stream:
writer = csv.writer(stream)
# Write the header row
writer.writerow(first_key(d) for d in project_index)
# Write the rest
rows = zip(*[first_value(d) for d in project_index])
writer.writerows(rows)
Contents of output.csv:
A,B,C,D,D,F
1,4,7,10,13,16
2,5,8,11,14,17
3,6,9,12,15,18