I have the following data structure:
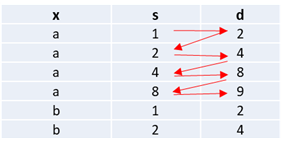
The columns "s" and "d" are indicating the transition of the object in column "x". What I want to do is get a transition string per object present in column "x". E.g. with a "new" column as follows:
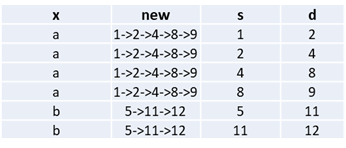
Is there a good way to do it using PySpark?
I tried the following PySpark code using udf, but it does not work:
from pyspark.sql.functions import udf
from pyspark.sql.functions import array_distinct
from pyspark.sql.types import ArrayType, StringType
create_transition = udf(lambda x: "->".join([i[0] for i in groupby(x)]))
df= df\
.withColumn('list', F.concat(df['s'], F.lit(','), df['d']))\
.groupBy('x').agg(F.collect_list('list').alias('list2'))\
.withColumn("list3", create_transition("list2"))
CodePudding user response:
If real values in columns "s" and "d" go in ascending order, then, using window partitions, you can:
- extract the
firstvalue from column "s" - extract all the values from column "d"
array_unionall the extracted valuesarray_sortandarray_joininto a string
w = W.partitionBy('x')
arr = F.array_union(F.array(F.first('s').over(w)), F.collect_list('d').over(w))
df = df.withColumn('new', F.array_join(F.array_sort(arr), '->'))
Full test:
from pyspark.sql import functions as F, Window as W
df = spark.createDataFrame(
[('a', 1, 2),
('a', 2, 4),
('a', 4, 8),
('a', 8, 9),
('b', 5, 11),
('b', 11, 12)],
['x', 's', 'd'])
w = W.partitionBy('x')
arr = F.array_union(F.array(F.first('s').over(w)), F.collect_list('d').over(w))
df = df.withColumn('new', F.array_join(F.array_sort(arr), '->'))
df.show()
# --- --- --- -------------
# | x| s| d| new|
# --- --- --- -------------
# | a| 1| 2|1->2->4->8->9|
# | a| 2| 4|1->2->4->8->9|
# | a| 4| 8|1->2->4->8->9|
# | a| 8| 9|1->2->4->8->9|
# | b| 5| 11| 5->11->12|
# | b| 11| 12| 5->11->12|
# --- --- --- -------------
CodePudding user response:
Try this spark.sql
spark.sql(s"""
with t1 ( select 'a' x , 1 s, 2 d union all
select 'a', 2, 4 union all
select 'a', 4, 8 union all
select 'a', 8, 9 union all
select 'b', 5, 11 union all
select 'b', 11, 12 ) ,
t2 ( select x, collect_list(s) s, collect_list(d) d from t1 group by x ),
t3 ( select x, array_union(s, d) sd from t2 )
select b.x , concat_ws('->',sd) new, s,d from t3 a
join t1 b on a.x=b.x
order by b.x,s
""").show(false)
--- ------------- --- ---
|x |new |s |d |
--- ------------- --- ---
|a |1->2->4->8->9|1 |2 |
|a |1->2->4->8->9|2 |4 |
|a |1->2->4->8->9|4 |8 |
|a |1->2->4->8->9|8 |9 |
|b |5->11->12 |5 |11 |
|b |5->11->12 |11 |12 |
--- ------------- --- ---