I have a column which I am splitting in Snowflake.
The format is as follows:
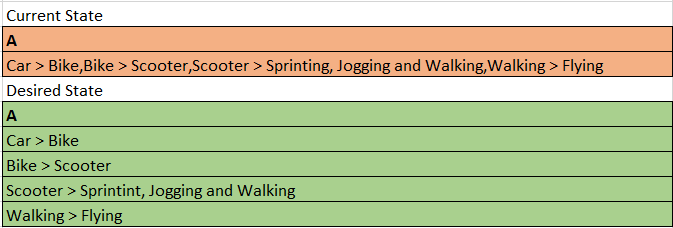
I have been using split_to_table(A, ',') inside of my query but as you can probably tell this uncorrectly also splits the Scooter > Sprinting, Jogging and Walking record.
Perhaps having the delimiter only work if there is no spaced on either side of it? As I cannot see a different condition that could work.
I have been researching online but haven't found a suitable work around yet, is there anyone that encountered a similar problem in the past?
Thanks
CodePudding user response:
This is a custom rule for the split to table, so we can use a UDTF to apply a custom rule:
create or replace function split_to_table2(STR string, DELIM string, ROW_MUST_CONTAIN string)
returns table (VALUE string)
language javascript
strict immutable
as
$$
{
initialize: function (argumentInfo, context) {
},
processRow: function (row, rowWriter, context) {
var buffer = "";
var i;
const s = row.STR.split(row.DELIM);
for(i=0; i<s.length-1; i ) {
buffer = s[i];
if(s[i 1].includes(row.ROW_MUST_CONTAIN)) {
rowWriter.writeRow({VALUE: buffer});
buffer = "";
} else {
buffer = row.DELIM
}
}
rowWriter.writeRow({VALUE: s[i]})
},
}
$$;
select VALUE from
table(split_to_table2('Car > Bike,Bike > Scooter,Scooter > Sprinting, Jogging and Walking,Walking > Flying', ',', '>'))
;
Output:
| VALUE |
|---|
| Car > Bike |
| Bike > Scooter |
| Scooter > Sprinting, Jogging and Walking |
| Walking > Flying |
This UDTF adds one more parameter than the two in the build in table function split_to_table. The third parameter, ROW_MUST_CONTAIN is the string a row must contain. It splits the string on DELIM, but if it does not have the ROW_MUST_CONTAIN string, it concatenates the strings to form a complete string for a row. In this case we just specify , for the delimiter and > for ROW_MUST_CONTAIN.
CodePudding user response:
Yes, you are right. The only pattern, which I can see, is the one with the whitespace after the comma.
It's a small workaround but we can make use of this pattern. In below code I am replacing such commas, where we do have whitespaces afterwards. Then I am applying split to table function and I am converting the previous replacement back.
It's not super pretty and would crash if your string contains "my_replacement" or any other new pattern, but its working for me:
select replace(t.value, 'my_replacement', ', ')
from table(
split_to_table(replace('Car > Bike,Bike > Scooter,Scooter > Sprinting, Jogging and Walking,Walking > Flying', ', ', 'my_replacement'),',')) t
CodePudding user response:
We can get a little clever with regexp_replace by replacing the actual delimiters with something else before the table split. I am using double pipes '||' but you can change that to something else. The '\|\|\\1' trick is called back-referencing that allows us to include the captured group (\\1) as part of replacement (\|\|)
set str='car>bike,bike>car,truck, and jeep,horse>cat,truck>car,truck, and jeep';
select $str, *
from table(split_to_table(regexp_replace($str,',([^>,] >)','\|\|\\1'),'||'))