My python code:
import pandas as pd
student_dict = {
"ID":[101,102,103,104,105],
"Student":["AAA","BBB","CCC","DDD","EEE"],
"Mark":[50,100,99,60,80],
"Address":["St.AAA","St.BBB","St.CCC","St.DDD","St.EEE"],
"PhoneNo":[1111111111,2222222222,3333333333,4444444444,5555555555]
}
df = pd.DataFrame(student_dict)
print("First dataframe")
print(df)
fName = "Student_CSVresult.csv"
def dups(df):
df = df.drop_duplicates(keep=False)
return df
try:
data = pd.read_csv(fName)
print("CSV file data")
print(data)
df_merged = pd.concat([data, df])
df = dups(df_merged)
print("After removing dups")
print(df)
df.to_csv(fName, mode='a', index=False,header=False)
except FileNotFoundError:
print("File Not Found Error")
df = df.drop_duplicates()
df.to_csv(fName, index=False)
print("New file created and data imported")
except Exception as e:
print(e)
on the first run, all data was imported without any copies.
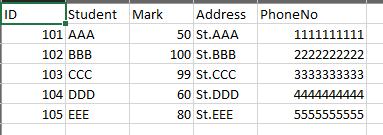
I gave a different dataframe in the next run
student_dict = {
"ID":[101,102,103,104,105,101,102,103,104,105,106,107],
"Student":["AAA","BBB","CCC","DDD","EEE","AAA","BBB","CCC","DDD","EEE","YYY","ZZZ"],
"Mark":[50,100,99,60,80,50,100,99,60,80,100,80],
"Address":["St.AAA","St.BBB","St.CCC","St.DDD","St.EEE","St.AAA","St.BBB","St.CCC","St.DDD","St.EEE","St.AYE","St.ZZZ"],
"PhoneNo":[1111111111,2222222222,3333333333,4444444444,5555555555,1111111111,2222222222,3333333333,4444444444,5555555555,6666666666,7777777777]
}
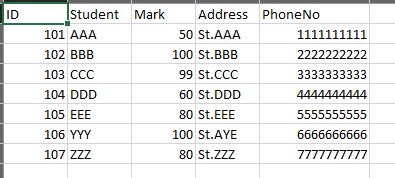
also no issues, then I gave the first dataframe again.
student_dict = {
"ID":[101,102,103,104,105],
"Student":["AAA","BBB","CCC","DDD","EEE"],
"Mark":[50,100,99,60,80],
"Address":["St.AAA","St.BBB","St.CCC","St.DDD","St.EEE"],
"PhoneNo":[1111111111,2222222222,3333333333,4444444444,5555555555]
}
and it created copies
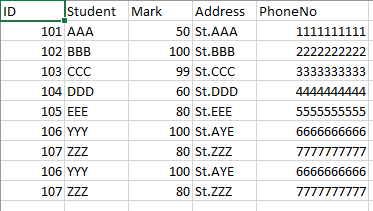
Can someone help me how to solve this issue? i don't want to overwrite the main file(Student_CSVresult.csv), just append only
also, is there any way to create a new column in the file that will auto-capture the timestamp of the data entry?
CodePudding user response:
A description of your program at the moment:
dfcontains new records.- The content of "Student_CSVresult.csv" is loaded into
data dfanddataare merged intodf_merged- Duplicates are removed from
df_mergedwithkeep=False, so thatdf_mergedcontains only records that appear exactly once in eitherdfordata - Content of
df_mergedis appended to "Student_CSVresult.csv"
I don't think this is quite what you are trying to do. The problem is in this step:
- Duplicates are removed from
df_mergedwithkeep=False, so thatdf_mergedcontains only records that appear exactly once in eitherdfordata
In the third step in your test, when you present the data from the first step again, the records that are presented in Step 2 but not in Step 1 occur exactly once (in the csv file only), so they are appended to the csv file resulting in duplicates in the csv file, which doesn't appear to be what you want.
It is not 100% clear in your question, but I think you want to append a single instance of any records in the newly presented student data that are not already in the csv file to the csv. To do this you'll need to find the records that are present in the new data but not in the csv file. The way to do this is described in this answer. Here's a function I wrote based on it:
def in_df2_only(df1, df2):
merged = pd.merge(df1, df2, how='outer', indicator=True)
return merged[merged['_merge'] == 'right_only'].drop(columns=['_merge'])
In my edit of your code I changed some variable names etc. to make the code more readable, and made a loop to run all three steps of the test in one go so I didn't have to run the program three times replacing student_dict for every test:
import pandas as pd
student_dicts = [
{
"ID":[101,102,103,104,105],
"Student":["AAA","BBB","CCC","DDD","EEE"],
"Mark":[50,100,99,60,80],
"Address":["St.AAA","St.BBB","St.CCC","St.DDD","St.EEE"],
"PhoneNo":[1111111111,2222222222,3333333333,4444444444,5555555555]
},
{
"ID":[101,102,103,104,105,101,102,103,104,105,106,107],
"Student":["AAA","BBB","CCC","DDD","EEE","AAA","BBB","CCC","DDD","EEE","YYY","ZZZ"],
"Mark":[50,100,99,60,80,50,100,99,60,80,100,80],
"Address":["St.AAA","St.BBB","St.CCC","St.DDD","St.EEE","St.AAA","St.BBB","St.CCC","St.DDD","St.EEE","St.AYE","St.ZZZ"],
"PhoneNo":[1111111111,2222222222,3333333333,4444444444,5555555555,1111111111,2222222222,3333333333,4444444444,5555555555,6666666666,7777777777]
},
{
"ID":[101,102,103,104,105],
"Student":["AAA","BBB","CCC","DDD","EEE"],
"Mark":[50,100,99,60,80],
"Address":["St.AAA","St.BBB","St.CCC","St.DDD","St.EEE"],
"PhoneNo":[1111111111,2222222222,3333333333,4444444444,5555555555]
},
]
fName = "Student_CSVresult.csv"
# ====================
def in_df2_only(df1, df2):
merged = pd.merge(df1, df2, how='outer', indicator=True)
return merged[merged['_merge'] == 'right_only'].drop(columns=['_merge'])
# ====================
for student_dict in student_dicts:
student_df = pd.DataFrame(student_dict)
print("Student data: ")
print(student_df)
try:
csv_data = pd.read_csv(fName)
print("Existing CSV data: ")
print(csv_data)
not_in_csv = in_df2_only(df1=csv_data, df2=student_df)
not_in_csv.drop_duplicates().to_csv(fName, mode='a', index=False, header=False)
print("Records added to CSV: ")
print(not_in_csv)
except FileNotFoundError:
print("File Not Found Error")
student_df = student_df.drop_duplicates()
student_df.to_csv(fName, index=False)
print("New file created and data imported")
except Exception as e:
print(e)
print()
print('====================')
print()
The final content of the csv file is:
ID,Student,Mark,Address,PhoneNo
101,AAA,50,St.AAA,1111111111
102,BBB,100,St.BBB,2222222222
103,CCC,99,St.CCC,3333333333
104,DDD,60,St.DDD,4444444444
105,EEE,80,St.EEE,5555555555
106,YYY,100,St.AYE,6666666666
107,ZZZ,80,St.ZZZ,7777777777