I have a few things to get clear, specifically regarding modeling architecture for a serverless application using AWS CDK.
I’m currently working on a serverless application developed using AWS CDK in TypeScript. Also as a convention, we follow the below rules too.
- A stack should only have one table (dynamo)
- A stack should only have one REST API (api-gateway)
- A stack should not depend on any other stack (no cross-references), unless its the Event-Stack (a stack dedicated to managing EventBridge operations)
The reason for that is so that each stack can be deployed independently without any interferences of other stacks. In a way, our stacks are equivalent to micro-services in a micro-service architecture.
At the moment all the REST APIs are public and now we have decided to make them private by attaching custom Lambda authorizers to each API Gateway resource. Now, in this custom Lambda authorizer, we have to do certain operations (apart from token validation) in order to allow the user's request to proceed further. Those operations are,
- Get the user’s role from DB using the user ID in the token
- Get the user’s subscription plan (paid, free, etc.) from DB using the user ID in the token.
- Get the user’s current payment status (due, no due, fully paid, etc.) from DB using the user ID in the token.
- Get scopes allowed for this user based on 1. 2. And 3.
- Check whether the user can access this scope (the resource user currently requesting) based on 4.
This authorizer Lambda function needs to be used by all the other Stacks to make their APIs private. But the problem is roles, scopes, subscriptions, payments & user data are in different stacks in their dedicated DynamoDB tables. Because of the rules, I have explained before (especially rule number 3.) we cannot depend on the resources defined in other stacks. Hence we are unable to create the Authoriser we want.
Solutions we could think of and their problems:
- Since EventBridge isn't bi-directional we cannot use it to fetch data from a different stack resource.
- We can
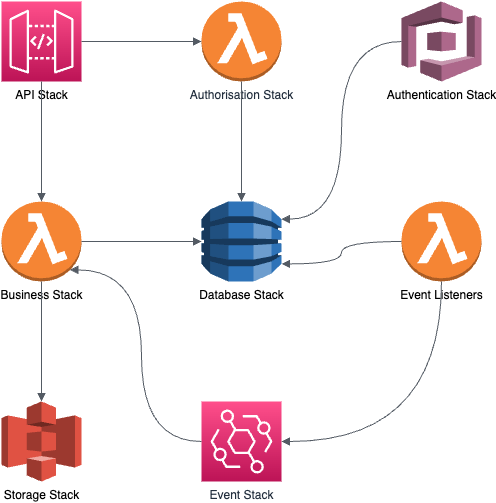
As you can see, now stacks are going to have multiple dependencies with other stacks' resources (But no circular dependencies, as shown in the attached image). While this pattern unblocks us from writing an effective custom Lambda authorizer we are not sure whether this pattern won't be a problem in the long run, when the application's scope increases.
I highly appreciate the help any one of you could give us to resolve this problem. Thanks!
CodePudding user response:
Multiple options:
Use Parameter Store rather than CloudFormation exports
Split stacks into a layered architecture like you described in your answer and import things between Stacks using SSM parameter store like the other answer describes. This is the most obvious choice for breaking inter-stack dependencies. I use it all the time.
Use fixed resource names, easily referencable and importable
Stack A creates S3 bucket "myapp-users", Stack B imports S3 bucket by fixed name using Bucket.fromBucketName(this, 'Users', 'myapp-users'). Fixed resource names have their own downsides, so this should be used only for resources that are indeed shared between stacks. They prevent easy replacement of the resource, for example. Also, you need to enforce the correct Stack deployment order, CDK will not help you with that anymore since there are no cross-stack dependencies to enforce it.
Combine the app into a single stack
This sounds extreme and counter intuitive, but I found that most real life teams don't actually have a pressing need for multi-stack deployment. If your only concern is separating code-owners of different parts of the application - you can get away by splitting the stack into multiple Constructs, composed into a single stack, where each team takes care of their Construct and its children. Think of it as combining multiple Git repos into a Monorepo. A lot of projects are doing that.
CodePudding user response:
A strategy I use to avoid hard cross-references involves storing shared resource values in
AWS Systems Manager.In the exporting stack, we can save the name of an S3 Bucket for instance:
ssm.StringParameter( scope=self, id="/example_stack/example_bucket_name", string_value=self.example_bucket.bucket_name, parameter_name="/example_stack/example_bucket_name", )and then in the importing stack, retrieve the name and create an
IBucketby using a.from_method.example_bucket_name = ssm.StringParameter.value_for_string_parameter( scope=self, parameter_name="/example_stack/example_bucket_name", ) example_bucket = s3.Bucket.from_bucket_name( scope=self, id="example_bucket_from_ssm", bucket_name=example_bucket_name, )You'll have to figure out the right order to deploy your stacks but otherwise, I've found this to be a good strategy to avoid the issues encountered with stack dependencies.