Basically, what I want to achieve is the following binary transformation with the following conditions:
If all the values in C2 associated with a variable in C1 has never been greater than 0, keep only 1 record of it (C & G) with its associated value to be 0 even if it appears multiple times.
If some of the values in C2 associated with a variable in C1 has a value greater than 0, keep all those records of it with its associated value to be 1 and eliminate the ones with zero (A, B, D, E & F).
-----------------
| C1 | C2 |
--------|--------
| A | 6 |
| B | 5 |
| C | 0 |
| A | 0 |
| D | 1 |
| E | 4 |
| F | 9 |
| B | 0 |
| C | 0 |
| G | 0 |
| D | 0 |
| D | 7 |
| G | 0 |
| G | 0 |
-----------------
to
-----------------
| C1 | C2 |
--------|--------
| A | 1 |
| B | 1 |
| C | 0 |
| D | 1 |
| D | 1 |
| E | 1 |
| F | 1 |
| G | 0 |
-----------------
How does one attain this in PySpark?
CodePudding user response:
heres the implementation
from pyspark.sql import functions as F
df = spark.createDataFrame(
[
("A", 6),
("B", 5),
("C", 0),
("A", 0),
("D", 1),
("E", 4),
("F", 9),
("B", 0),
("C", 0),
("G", 0),
("D", 0),
("D", 7),
("G", 0),
("G", 0),
],
["C1", "C2"],
)
df1 = (df
.groupBy("C1")
.agg(max("C2").alias("C2"))
.filter(F.col("C2") == 0)
)
df2 = (df
.filter(F.col("C2") > 0)
.withColumn("C2", F.lit(1))
)
final_df = df1.unionAll(df2).orderBy("C1")
df1.show()
df2.show()
final_df.show()
output:
--- ---
| C1| C2|
--- ---
| C| 0|
| G| 0|
--- ---
--- ---
| C1| C2|
--- ---
| A| 1|
| B| 1|
| D| 1|
| E| 1|
| F| 1|
| D| 1|
--- ---
--- ---
| C1| C2|
--- ---
| A| 1|
| B| 1|
| C| 0|
| D| 1|
| D| 1|
| E| 1|
| F| 1|
| G| 0|
--- ---
CodePudding user response:
Here are my 2 cents
Create a spark data frame.
df = spark.createDataFrame([('A', 6) ,('B', 5) ,('C', 0) ,('A', 0) ,('D', 1) ,('E', 4) ,('F', 9) ,('B', 0) ,('C', 0) ,('G', 0) ,('D', 0) ,('D', 7) ,('G', 0) ,('G', 0) ], schema = ['c1','c2'])Here we are using collect_list() to actually to order the collected results depends on the order of the C1 and then we are keeping the distinct elements
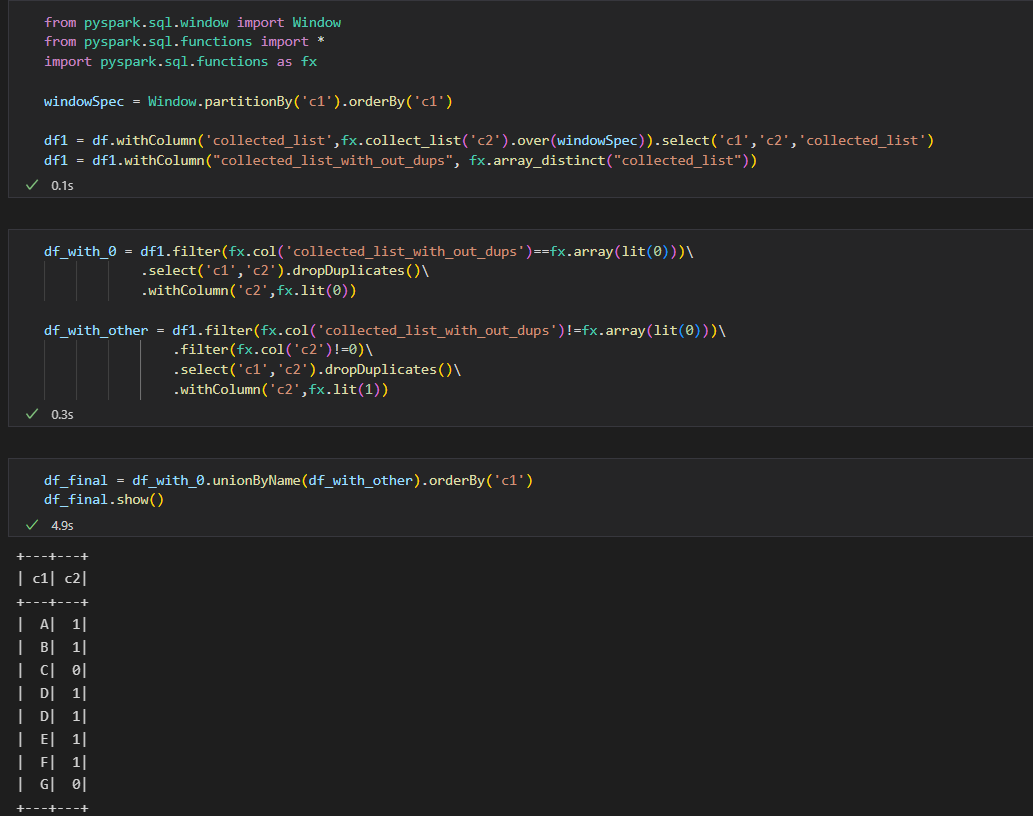
from pyspark.sql.window import Window from pyspark.sql.functions import * import pyspark.sql.functions as fx windowSpec = Window.partitionBy('c1').orderBy('c1') df1 = df.withColumn('collected_list',fx.collect_list('c2').over(windowSpec)).select('c1','c2','collected_list') df1 = df1.withColumn("collected_list_with_out_dups", fx.array_distinct("collected_list"))
3a. Create data frame with 0's first:
df_with_0 = df1.filter(fx.col('collected_list_with_out_dups')==fx.array(lit(0)))\
.select('c1','c2').dropDuplicates()\
.withColumn('c2',fx.lit(0))
df_with_0.show()
3b. create data frame with the other values other than 0 as follows:
df_with_other = df1.filter(fx.col('collected_list_with_out_dups')!=fx.array(lit(0)))\
.filter(fx.col('c2')!=0)\
.select('c1','c2').dropDuplicates()\
.withColumn('c2',fx.lit(1))
df_with_other.show()
Print the df_final dataframe as follows:
df_final = df_with_0.unionByName(df_with_other).orderBy('c1') df_final.show()
Please check the below screenshot for your reference: