I am trying to store data from data frames and write it into in an excel sheet (same work sheet) without overwriting. But my script just overwrites the entire sheet. I want all the data to be stored with same column names as it is in the data frames.
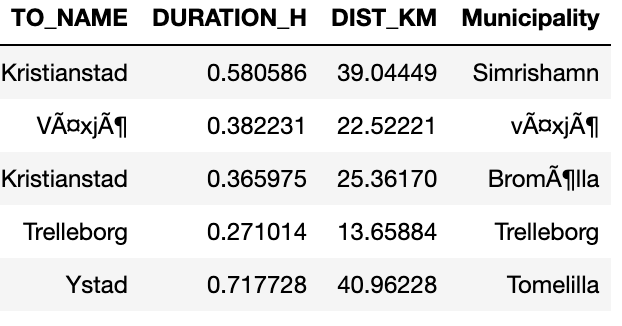
Data Sample:
TO_NAME DURATION_H DIST_KM Municipality
Kristianstad 0.580586 39.04449 Simrishamn
Växjö 0.382231 22.52221 växjö
Kristianstad 0.365975 25.36170 Bromölla
Trelleborg 0.271014 13.65884 Trelleborg
Ystad 0.717728 40.96228 Tomelilla
I have tried to store the data in seperate data frames and then write into an excel file but still it overwrites the data. The sheet_name are different.
Here is my sample code:
df1_Regular_Ambulance_TT = pd.DataFrame()
df2_Regular_Ambulance_TT = pd.DataFrame()
df1_Regular_Ambulance_TT["Ambulance_ID"] = Regular_Ambulance_TT["Ambulance_ID"]
df2_Regular_Ambulance_TT["Centroid_ID"] = Regular_Ambulance_TT["Centroid_ID"]
df1_Regular_Ambulance_TT.to_excel(r'/Users/an2178/Desktop/Jupyter Notebook/Regular-Ambulance-Complete-TT.xlsx', sheet_name='Base_TT', index = False)
df2_Regular_Ambulance_TT.to_excel(r'/Users/an2178/Desktop/Jupyter Notebook/Regular-Ambulance-Complete-TT.xlsx', sheet_name='Centroid_ID', index = False)
I want to store my data like this in an excel sheet in the same work sheet:
How to avoid overwriting while storing multicolumns from data frames to an excel sheet in similar sheet?
CodePudding user response:
You can use Column to add up multi data into the same work sheet in an excel sheet.
This should work:
Regular_Ambulance_TT. to_excel(r'/Users/an2178/Desktop/Jupyter Notebook/Regular-Ambulance-Complete-TT.xlsx', columns = ['column1','column2','column3','column4'], index = False)