My Pandas data frame contains the following data reading from a csv file:
id,values
1001-MAC, 10
1034-WIN, 20
2001-WIN, 15
3001-MAC, 45
4001-LINUX, 12
4001-MAC, 67
df = pd.read_csv('example.csv')
df.set_index('id', inplace=True)
I have to sort this data frame based on the id column order by given suffix list = ["WIN", "MAC", "LINUX"]. Thus, I would like to get the following output:
id,values
1034-WIN, 20
2001-WIN, 15
1001-MAC, 10
3001-MAC, 45
4001-MAC, 67
4001-LINUX, 12
How can I do that?
CodePudding user response:
Here is one way to do that:
import pandas as pd
df = pd.read_csv('example.csv')
idx = df.id.str.split('-').str[1].sort_values(ascending=False).index
df = df.loc[idx]
df.set_index('id', inplace=True)
print(df)
CodePudding user response:
Try:
df = df.sort_values(
by=["id"], key=lambda x: x.str.split("-").str[1], ascending=False
)
print(df)
Prints:
id values
1 1034-WIN 20
2 2001-WIN 15
0 1001-MAC 10
3 3001-MAC 45
5 4001-MAC 67
4 4001-LINUX 12
CodePudding user response:
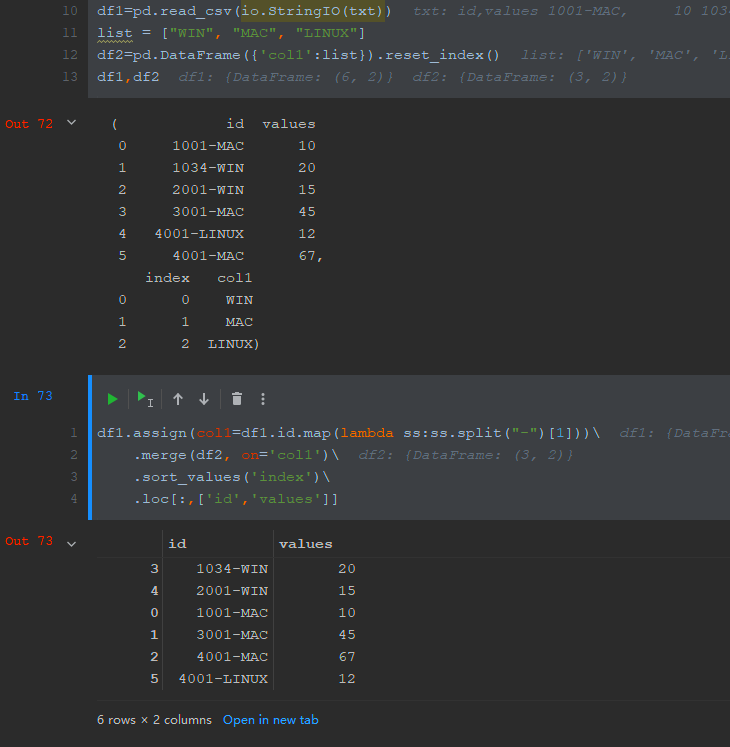
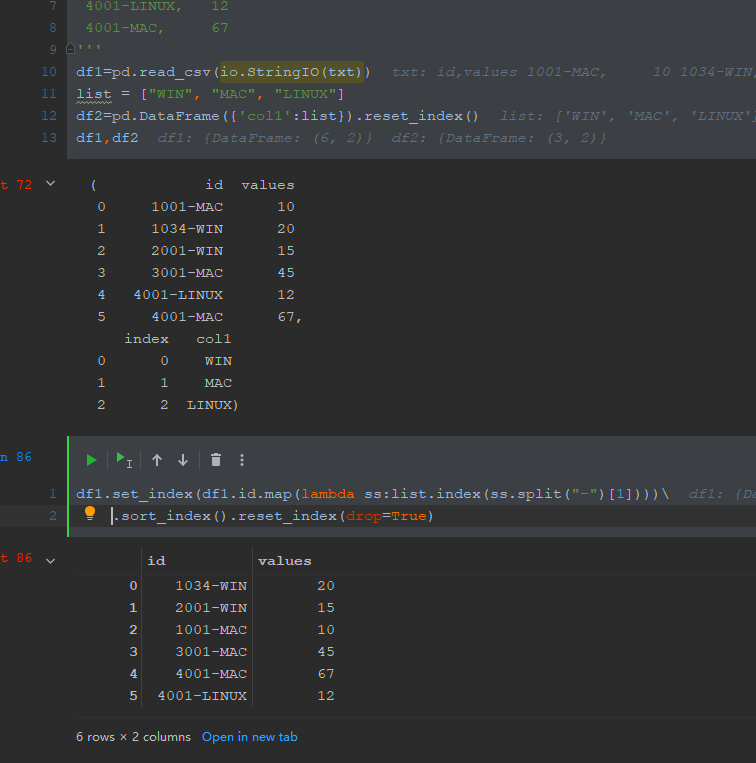
Add a column to a dataframe that would contain only prefixes (use str.split() function for that) and sort whole df based on that new column.
CodePudding user response:
import pandas as pd
df = pd.DataFrame({
"id":["1001-MAC", "1034-WIN", "2001-WIN", "3001-MAC", "4001-LINUX", "4001-MAC"],
"values":[10, 20, 15, 45, 12, 67]
})
df["id_postfix"] = df["id"].apply(lambda x: x.split("-")[1])
df = df.sort_values("id_postfix", ascending=False)
df = df[["id", "values"]]
print(df)
CodePudding user response:
 Please be sure to answer the question. Provide details and share your research!
Please be sure to answer the question. Provide details and share your research!
CodePudding user response:
Please be sure to answer the question. Provide details and share your research!