I have the following DataFrame (Date in dd-mm-yyyy format):
import pandas as pd
data={'Id':['A', 'B', 'C', 'A', 'B', 'C', 'B', 'C', 'A', 'C', 'B', 'C', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C'],
'Date':['20-10-2022', '20-10-2022', '20-10-2022', '21-10-2022', '21-10-2022', '21-10-2022',
'22-10-2022', '22-10-2022', '23-10-2022', '23-10-2022', '24-10-2022', '24-10-2022',
'25-10-2022', '25-10-2022', '26-10-2022', '26-10-2022', '26-10-2022', '27-10-2022',
'27-10-2022', '27-10-2022']}
df=pd.DataFrame.from_dict(data)
df
Id Date
0 A 20-10-2022
1 B 20-10-2022
2 C 20-10-2022
3 A 21-10-2022
4 B 21-10-2022
5 C 21-10-2022
6 B 22-10-2022
7 C 22-10-2022
8 A 23-10-2022
9 C 23-10-2022
10 B 24-10-2022
11 C 24-10-2022
12 B 25-10-2022
13 C 25-10-2022
14 A 26-10-2022
15 B 26-10-2022
16 C 26-10-2022
17 A 27-10-2022
18 B 27-10-2022
19 C 27-10-2022
This is the Final DataFrame that I want:
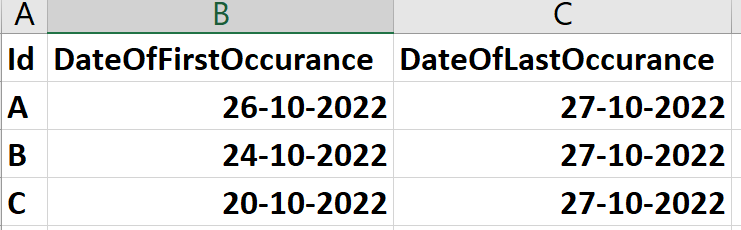
I have tried the following code:
# Find first occurance and last occurance of any given Id.
df_first_duplicate = df.drop_duplicates(subset=['Id'], keep='first')
df_first_duplicate.rename(columns = {'Date':'DateOfFirstOccurance'}, inplace = True)
df_first_duplicate.reset_index(inplace = True, drop = True)
df_last_duplicate = df.drop_duplicates(subset=['Id'], keep='last')
df_last_duplicate.rename(columns = {'Date':'DateOfLastOccurance'}, inplace = True)
df_last_duplicate.reset_index(inplace = True, drop = True)
# Merge the above two df's on key
df_merged = pd.merge(df_first_duplicate, df_last_duplicate, on='Id')
df_merged
But this is the output that I get:
Id DateOfFirstOccurance DateOfLastOccurance
0 A 20-10-2022 27-10-2022
1 B 20-10-2022 27-10-2022
2 C 20-10-2022 27-10-2022
What should I do to get the desired output?
CodePudding user response:
Here is one way to do it.
Sort your data by Id and Date. Use pandas.Series.diff to get the difference of each row compared to the last one, change it with dt.days to a floating number and create a boolean Series by comparing each value if it is greater/equal to 1. Convert the boolean Series from True/False to 1/0 with astype(int) and build the cumulative sum. The idx with the biggest value is the first/last occurence of your data.
df['Date'] = pd.to_datetime(df['Date'], infer_datetime_format=True)
df = df.sort_values(['Id', 'Date'])
out = (
df
.groupby('Id')['Date']
.agg(
first_occurence = lambda x: x[
(x.diff().dt.days>1)
.astype(int)
.cumsum()
.idxmax()
],
last_occurence = lambda x: x[
(x.diff().dt.days==1)
.astype(int)
.cumsum()
.idxmax()
],
)
)
print(out)
CodePudding user response:
df['Date'] = pd.to_datetime(df['Date'], format='%d-%m-%Y')
records = []
for key, group in df.groupby(by='Id'):
filt = group['Date'].diff(-1).dt.days >= -1
filt.iloc[filt.shape[0]-1] = True
max_false_index = filt[~filt].index.max()
min_date = group['Date'].min() if type(max_false_index) == float else group.loc[max_false_index 1:, 'Date'].min()
records.append([key, min_date, group['Date'].max()])
pd.DataFrame(records, columns=['Id', 'DateOfFirstOccurance', 'DateOfLastOccurance'])