I have a situation where I need to compare multiple pairs of columns (the number of pairs will vary and can come from a list as shown in below code snippet) and get 1/0 flag for match/mismatch respectively. Eventually use this to identify the number of records/rows with mismatch and % records mismatched
NONKEYCOLS= ['Marks', 'Qualification']
The first image is source df and second image is expected df.
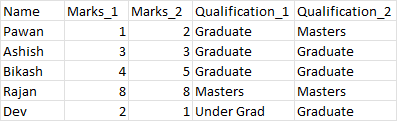
[

Since this is happening for multiple pairs on a loop, it is very slow for about a billion records. Need help with something efficient.
I have the below code but the part that calculates change records is taking long time.
for ind,cols in enumerate(NONKEYCOLS):
print(ind)
print(cols)
globals()['new_dataset' '_char_changes_tmp']=globals()['new_dataset' '_char_changes_tmp']\
.withColumn("records_changed" str(ind),\
F.sum(col("records_ch_flag_" str(ind)))\
.over(w1))
globals()['new_dataset' '_char_changes_tmp']=globals()['new_dataset' '_char_changes_tmp']\
.withColumn("records_changed" str(ind),\
F.sum(col("records_ch_flag_" str(ind)))\
.over(w1))
globals()['new_dataset' '_char_changes_tmp']=globals()['new_dataset' '_char_changes_tmp']\
.withColumn("records_changed_cnt" str(ind),\
F.count(col("records_ch_flag_" str(ind)))\
.over(w1))
CodePudding user response:
i'm not sure what loop are you running, but here's an implementation with list comprehension within a select.
data_ls = [
(10, 11, 'foo', 'foo'),
(12, 12, 'bar', 'bar'),
(10, 12, 'foo', 'bar')
]
data_sdf = spark.sparkContext.parallelize(data_ls). \
toDF(['marks_1', 'marks_2', 'qualification_1', 'qualification_2'])
col_pairs = ['marks','qualification']
data_sdf. \
select('*',
*[(func.col(c '_1') == func.col(c '_2')).cast('int').alias(c '_check') for c in col_pairs]
). \
show()
# ------- ------- --------------- --------------- ----------- -------------------
# |marks_1|marks_2|qualification_1|qualification_2|marks_check|qualification_check|
# ------- ------- --------------- --------------- ----------- -------------------
# | 10| 11| foo| foo| 0| 1|
# | 12| 12| bar| bar| 1| 1|
# | 10| 12| foo| bar| 0| 0|
# ------- ------- --------------- --------------- ----------- -------------------
where the list comprehension would yield the following
[(func.col(c '_1') == func.col(c '_2')).cast('int').alias(c '_check') for c in col_pairs]
# [Column<'CAST((marks_1 = marks_2) AS INT) AS `marks_check`'>,
# Column<'CAST((qualification_1 = qualification_2) AS INT) AS `qualification_check`'>]
EDIT
based on the additional (updated) info, you need the count of unmatched records for that pair and then you want to calculate the unmatched percentage.
reversing the aforementioned logic to count the unmatched records
col_pairs = ['marks','qualification']
data_sdf. \
agg(*[func.sum((func.col(c '_1') != func.col(c '_2')).cast('int')).alias(c '_unmatch') for c in col_pairs],
func.count('*').alias('row_cnt')
). \
select('*',
*[(func.col(c '_unmatch') / func.col('row_cnt')).alias(c '_unmatch_perc') for c in col_pairs]
). \
show()
# ------------- --------------------- ------- ------------------ --------------------------
# |marks_unmatch|qualification_unmatch|row_cnt|marks_unmatch_perc|qualification_unmatch_perc|
# ------------- --------------------- ------- ------------------ --------------------------
# | 2| 1| 3|0.6666666666666666| 0.3333333333333333|
# ------------- --------------------- ------- ------------------ --------------------------
the code flags (as 1) the records where the pair does not match and takes a sum of the flag - which gives us the pair's unmatched record count. dividing that with the total row count will give the percentage.
the list comprehension will yield the following
[func.sum((func.col(c '_1') != func.col(c '_2')).cast('int')).alias(c '_unmatch') for c in col_pairs]
# [Column<'sum(CAST((NOT (marks_1 = marks_2)) AS INT)) AS `marks_unmatch`'>,
# Column<'sum(CAST((NOT (qualification_1 = qualification_2)) AS INT)) AS `qualification_unmatch`'>]
this is very much efficient as all of it happens in a single select statement which will only project once in the spark plan as opposed to your approach which will project every time you do a withColumn - and that is inefficient to spark.
CodePudding user response:
df.colRegex may serve you well. If all the values in columns which match the regex are equal, you get 1. The script is efficient, as everything is done in one select.
Inputs:
from pyspark.sql import functions as F
df = spark.createDataFrame(
[('p', 1, 2, 'g', 'm'),
('a', 3, 3, 'g', 'g'),
('b', 4, 5, 'g', 'g'),
('r', 8, 8, 'm', 'm'),
('d', 2, 1, 'u', 'g')],
['Name', 'Marks_1', 'Marks_2', 'Qualification_1', 'Qualification_2'])
col_pairs = ['Marks', 'Qualification']
Script:
def equals(*cols):
return (F.size(F.array_distinct(F.array(*cols))) == 1).cast('int')
df = df.select(
'*',
*[equals(df.colRegex(f"`^{c}.*`")).alias(f'{c}_result') for c in col_pairs]
)
df.show()
# ---- ------- ------- --------------- --------------- ------------ --------------------
# |Name|Marks_1|Marks_2|Qualification_1|Qualification_2|Marks_result|Qualification_result|
# ---- ------- ------- --------------- --------------- ------------ --------------------
# | p| 1| 2| g| m| 0| 0|
# | a| 3| 3| g| g| 1| 1|
# | b| 4| 5| g| g| 0| 1|
# | r| 8| 8| m| m| 1| 1|
# | d| 2| 1| u| g| 0| 0|
# ---- ------- ------- --------------- --------------- ------------ --------------------
Proof of efficiency:
df.explain()
# == Physical Plan ==
# *(1) Project [Name#636, Marks_1#637L, Marks_2#638L, Qualification_1#639, Qualification_2#640, cast((size(array_distinct(array(Marks_1#637L, Marks_2#638L)), true) = 1) as int) AS Marks_result#646, cast((size(array_distinct(array(Qualification_1#639, Qualification_2#640)), true) = 1) as int) AS Qualification_result#647]
# - Scan ExistingRDD[Name#636,Marks_1#637L,Marks_2#638L,Qualification_1#639,Qualification_2#640]
Edit:
def equals(*cols):
return (F.size(F.array_distinct(F.array(*cols))) != 1).cast('int')
df = df.select(
'*',
*[equals(df.colRegex(f"`^{c}.*`")).alias(f'{c}_result') for c in col_pairs]
).agg(
*[F.sum(f'{c}_result').alias(f'rec_changed_{c}') for c in col_pairs],
*[(F.sum(f'{c}_result') / F.count(f'{c}_result')).alias(f'{c}_%_rec_changed') for c in col_pairs]
)
df.show()
# ----------------- ------------------------- ------------------- ---------------------------
# |rec_changed_Marks|rec_changed_Qualification|Marks_%_rec_changed|Qualification_%_rec_changed|
# ----------------- ------------------------- ------------------- ---------------------------
# | 3| 2| 0.6| 0.4|
# ----------------- ------------------------- ------------------- ---------------------------