I have the following live table
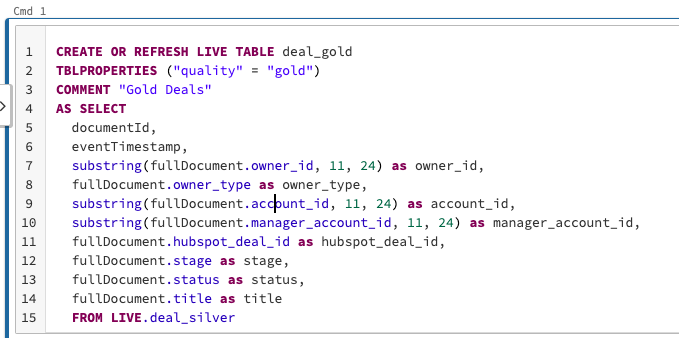
And i'm looking to write that into a stream to be written back into my kafka source.
I've seen in the apache spark docs that I can use writeStream ( I've used readStream to get it out of my kafka stream already ). But how do I transform the table into the medium it needs so it can use this?
I'm fairly new to both kafka and the data world so any further explanation's are welcome here.
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
Thanks in Advance,
Ben
I've seen in the apache spark docs that I can use writeStream ( I've used readStream to get it out of my kafka stream already ). But how do I transform the table into the medium it needs so it can use this?I'm fairly new to both kafka and the data world so any further explanation's are welcome here.
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
CodePudding user response:
The transformation is done after the read stream process is started
read_df = spark.readStream.format('kafka') ... .... # other options
processed_df = read_df.withColumn('some column', some_calculation )
processed_df.writeStream.format('parquet') ... .... # other options
.start()
The spark documentation is helpful and detailed but some articles are not for beginners. You can look on youtube or read articles to help you get started like this one
CodePudding user response:
As of right now, Delta Live Tables can only write data as a Delta table - it's not possible to write in other formats. You can implement a workaround by creating a Databricks workflow that consist of two tasks (with dependencies or not depending if the pipeline is triggered or not):
- DLT Pipeline that will do the actual data processing
- A task (easiest way to do with notebook) that will read a table generated by DLT as a stream and write its content into Kafka, with something like that:
df = spark.readStream.format("delta").table("database.table_name")
(df.write.format("kafka").option("kafka....", "")
.trigger(availableNow=True) # if it's not continuous
.start()
)
P.S. If you have solution architect or customer success engineer attached to your Databricks account, you can communicate this requirement to them for product prioritization.