I am creating a spark dataframe using the below query:
select distinct adr.ProductionDate,adr.CostCenterKey,adr.AEMainCategoryKey, Sum(adr.DurationDayFrac*adr.FixedCashCostAE)*100 / (select sum(adr_sub.DurationDayFrac*adr_sub.FixedCashCostAE)
from hive_metastore.oth_opsdbconf.operations_db___asset_effectiveness_daily_reporting adr_sub
where adr_sub.costcenterkey=adr.costcenterkey and adr_sub.ProductionDate=adr.ProductionDate
) as AELossMagnitude
FROM hive_metastore.oth_opsdbconf.operations_db___asset_effectiveness_daily_reporting adr
WHERE adr.DurationDayFrac != 0 AND adr.ProductionDate <= Current_Date()
AND adr.ProductionDate >= '2017-01-01'
AND adr.SiteName in ('Ludwigshafen','Schwarzheide','Antwerpen')
AND AreaIsCurrent = 'true'
group by adr.ProductionDate,adr.CostCenterKey,adr.AEMainCategoryKey
order by adr.ProductionDate,adr.CostCenterKey,adr.AEMainCategoryKey
But i am getting the below error:
AnalysisException: Correlated scalar subquery 'scalarsubquery(adr.costcenterkey, adr.ProductionDate)' is neither present in the group by, nor in an aggregate function. Add it to group by using ordinal position or wrap it in first() (or first_value) if you don't care which value you get.;
Request you to please help me with the correct syntax.
I am expecting the correct syntax to remove the error.z Its asking for group by in the sub query which is not possible.
CodePudding user response:
First, I don't understand why you need the distinct key word. I think the correlated sub-query will not work. Use a common table expression instead. Please see code below.
--
-- Use common table expression instead of correlated sub query
--
WITH cte_cost_by_center_n_date
(
SELECT
costcenterkey,
ProductionDate,
sum(DurationDayFrac * FixedCashCostAE) as TotalCost
FROM
hive_metastore.oth_opsdbconf.operations_db___asset_effectiveness_daily_reporting
GROUP BY
costcenterkey,
ProductionDate
)
SELECT
adr.ProductionDate,
adr.CostCenterKey,
adr.AEMainCategoryKey,
sum(adr.DurationDayFrac*adr.FixedCashCostAE) * 100 / adr_sub.TotalCost as AELossMagnitude
FROM
hive_metastore.oth_opsdbconf.operations_db___asset_effectiveness_daily_reporting as adr
JOIN
cte_cost_by_center_n_date as adr_sub
ON
adr_sub.costcenterkey = adr.costcenterkey
AND adr_sub.ProductionDate = adr.ProductionDate
WHERE
adr.DurationDayFrac != 0
AND adr.ProductionDate <= Current_Date()
AND adr.ProductionDate >= '2017-01-01'
AND adr.SiteName in ('Ludwigshafen','Schwarzheide','Antwerpen')
AND adr.AreaIsCurrent = 'true'
GROUP BY
adr.ProductionDate,
adr.CostCenterKey,
adr.AEMainCategoryKey
ORDER BY
adr.ProductionDate,
adr.CostCenterKey,
adr.AEMainCategoryKey
CodePudding user response:
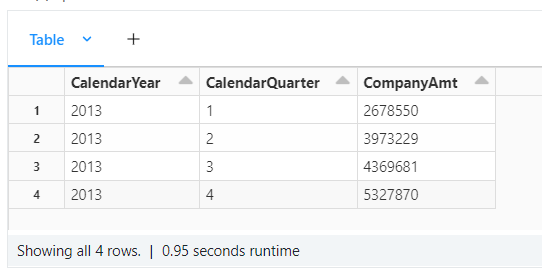
Here is a data set that I have locally, Adventure works. Let's figure out sales at the company level regardless of region.
select
d.CalendarYear,
d.CalendarQuarter,
sum(s.SalesAmount) as CompanyAmt
from
star.fact_internet_sales as s
join
star.dim_date as d
on
s.OrderDateKey = d.DateKey
where
d.CalendarYear = 2013
group by
d.CalendarYear,
d.CalendarQuarter
order by
d.CalendarYear,
d.CalendarQuarter
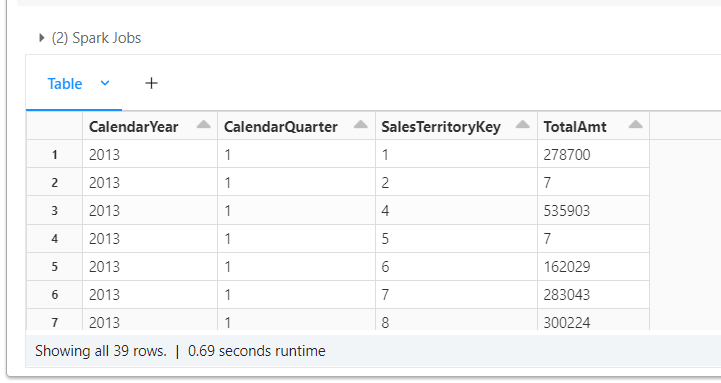
Next, lets figure out sales are the regional level (territory).
select
d.CalendarYear,
d.CalendarQuarter,
s.SalesTerritoryKey,
sum(s.SalesAmount) as RegionAmt
from
star.fact_internet_sales as s
join
star.dim_date as d
on
s.OrderDateKey = d.DateKey
where
d.CalendarYear = 2013
group by
d.CalendarYear,
d.CalendarQuarter,
s.SalesTerritoryKey
order by
d.CalendarYear,
d.CalendarQuarter,
s.SalesTerritoryKey
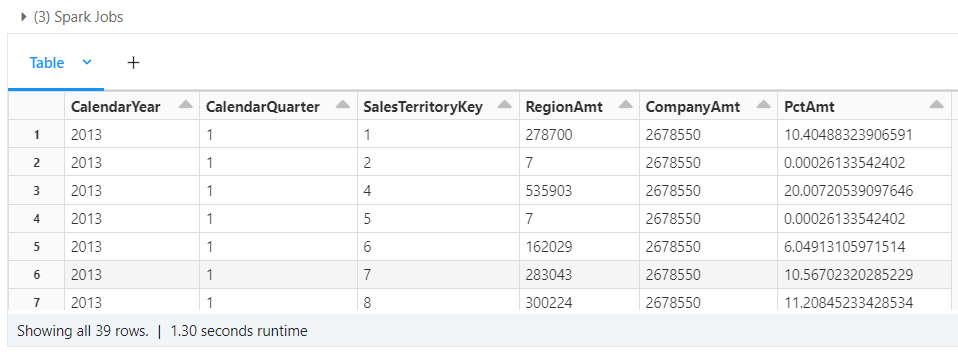
 Last, use the CTE to bring in a total so that we can figure out what percentage does each territory contribute to sales for a given quarter.
Last, use the CTE to bring in a total so that we can figure out what percentage does each territory contribute to sales for a given quarter.
-- Sales per qtr at company level
with cte_whole_company as
(
select
d.CalendarYear,
d.CalendarQuarter,
sum(s.SalesAmount) as CompanyAmt
from
star.fact_internet_sales as s
join
star.dim_date as d
on
s.OrderDateKey = d.DateKey
where
d.CalendarYear = 2013
group by
d.CalendarYear,
d.CalendarQuarter
order by
d.CalendarYear,
d.CalendarQuarter
)
-- Aggregated sales at territory with pct/contribution
select
d.CalendarYear,
d.CalendarQuarter,
s.SalesTerritoryKey,
sum(s.SalesAmount) as RegionAmt,
first(c.CompanyAmt) as CompanyAmt,
sum(s.SalesAmount) / first(c.CompanyAmt) * 100 as PctAmt
from
star.fact_internet_sales as s
join
star.dim_date as d
on
s.OrderDateKey = d.DateKey
join
cte_whole_company as c
on
d.CalendarYear = c.CalendarYear and
d.CalendarQuarter = c.CalendarQuarter
where
d.CalendarYear = 2013
group by
d.CalendarYear,
d.CalendarQuarter,
s.SalesTerritoryKey
order by
d.CalendarYear,
d.CalendarQuarter,
s.SalesTerritoryKey
My original statement that sub-queries can not be used in aggregations is true. Yes, you might be able to create a derived query or even create a temporary view, but I like common table expressions.