I'm sampling 3 numbers with their given probabilities, and I would like to turn the results into a data frame counting the occurrences of each value per sample.
Like this:
[0] [1] [2]
3 4 3
1 6 3
The code I am using to create the samples and count them is this:
replicate(10,table(sample(x=c(0,1,2), size=10, replace=TRUE, prob=c(.3,.4,.3))))
This gives me a result that can have a sample where only 2 of the numbers were selected. When I try to turn the samples into a data frame, I get an error given that those samples with only 2 numbers selected don't match the number of columns that the other samples have (see the below images for reference). Any ideas on how to get the data frame to fill the row of 2 counts with a third count that is 0 but respecting the order of the rows (i.e. can't only add 0s to the end of the row if the value not counted is the first value)?
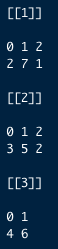

CodePudding user response:
It shouldn't hurt to add 1 to the vector v sampled from. Then we can use tabulate.
v <- c(0, 1, 2)
set.seed(118731)
r <- replicate(11, sample(v 1, size=10, replace=TRUE, prob=c(.3, .4, .3)))
apply(r, 2, table) ## fails
apply(r, 2, tabulate, nbins=length(v)) ## works
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11]
# [1,] 3 3 4 3 4 6 3 1 3 3 3
# [2,] 4 5 5 5 5 2 0 5 4 4 3
# [3,] 3 2 1 2 1 2 7 4 3 3 4
CodePudding user response:
One way is to create a factor and add levels explicitly:
replicate(
10, table(factor(
sample(x=c(0,1,2), size=10, replace=TRUE, prob=c(.3,.4,.3)),
levels = c(0,1,2))), simplify = F)
CodePudding user response:
You can try this brute force for loop:
set.seed(1237)
samp_data <- replicate(10, table(sample(x = c(0,1,2), size = 10, replace=TRUE, prob = c(0.3, 0.4, 0.3))))
for(i in seq_along(samp_data)){
samp_data[[i]][setdiff(as.character(0:2), names(samp_data[[i]]))] <- 0
}
Which will return a list with the 0 in the missing value. Then use do.call to make the table that outputs when there are no missing values:
do.call(cbind, samp_data)
Output
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
0 5 2 5 3 3 4 5 2 3 2
1 5 7 3 5 2 3 3 4 4 4
2 0 1 2 2 5 3 2 4 3 4
Im sure there are more elegant ways, but I couldn't get lapply to work!
CodePudding user response:
This approach replaces table altogether and simply adds to and rowSums a named vector.
set.seed(43)
vec <- c("0" = 0, "1" = 0, "2" = 0)
t(replicate(10, rowSums(sapply(
sample(x = names(vec), size=10, replace=TRUE, prob=c(.3,.4,.3)),
function(x){vec[x] <- vec[x] 1; vec}))))
0 1 2
[1,] 3 3 4
[2,] 0 7 3
[3,] 4 4 2
[4,] 2 5 3
[5,] 3 5 2
[6,] 2 5 3
[7,] 2 2 6
[8,] 4 3 3
[9,] 4 6 0
[10,] 1 5 4