I have a list of duplicate date ranges where I need to sum all dates unique to a campaign dates, without duplicating overlapping days.
For example in the data below, there are days in campaign_a running between 08/07/2022 and 15/07/2022 which overlap the 11/07/2022 and 13/07/2022 which need to not duplicate when summing.
The summing also needs to take the campaign name as a conditional.
| campaign | days | line_start | line_end |
|---|---|---|---|
| campaign_a | 108 | 14/07/2022 | 30/10/2022 |
| campaign_a | 61 | 31/10/2022 | 31/12/2022 |
| campaign_a | 2 | 11/07/2022 | 13/07/2022 |
| campaign_a | 2 | 8/07/2022 | 15/07/2022 |
| campaign_a | 108 | 14/07/2022 | 30/10/2022 |
| campaign_a | 61 | 31/10/2022 | 31/12/2022 |
| campaign_a | 2 | 11/07/2022 | 13/07/2022 |
| campaign_a | 2 | 8/07/2022 | 10/07/2022 |
| campaign_b | 108 | 14/07/2022 | 30/10/2022 |
| campaign_b | 61 | 31/10/2022 | 31/12/2022 |
| campaign_b | 2 | 11/07/2022 | 13/07/2022 |
| campaign_b | 2 | 8/07/2022 | 10/07/2022 |
| campaign_b | 108 | 14/07/2022 | 30/10/2022 |
| campaign_b | 61 | 31/10/2022 | 31/12/2022 |
| campaign_b | 2 | 11/07/2022 | 13/07/2022 |
| campaign_b | 2 | 8/07/2022 | 10/07/2022 |
| campaign_b | 108 | 14/07/2022 | 30/10/2022 |
| campaign_b | 61 | 31/10/2022 | 31/12/2022 |
| campaign_b | 2 | 11/07/2022 | 13/07/2022 |
| campaign_b | 2 | 8/07/2022 | 10/07/2022 |
CodePudding user response:
Again, assuming "campaign_a", for example, in G2:
=LET(
δ, A$2:D$21,
ζ, FILTER(δ, INDEX(δ, , 1) = G2),
α, INDEX(ζ, , 3),
β, INDEX(ζ, , 4),
ξ, SEQUENCE(MAX(β) - MIN(α) 1, , MIN(α)),
γ, BYROW(ξ, LAMBDA(λ, SUM(BYROW(CHOOSE({1, 2}, α, β),
LAMBDA(κ, N(MEDIAN(κ, λ) = λ)))))),
COUNT(FILTER(ξ, γ > 0))
)
Copy down to give similar results for campaigns in G3, G4, etc.
CodePudding user response:
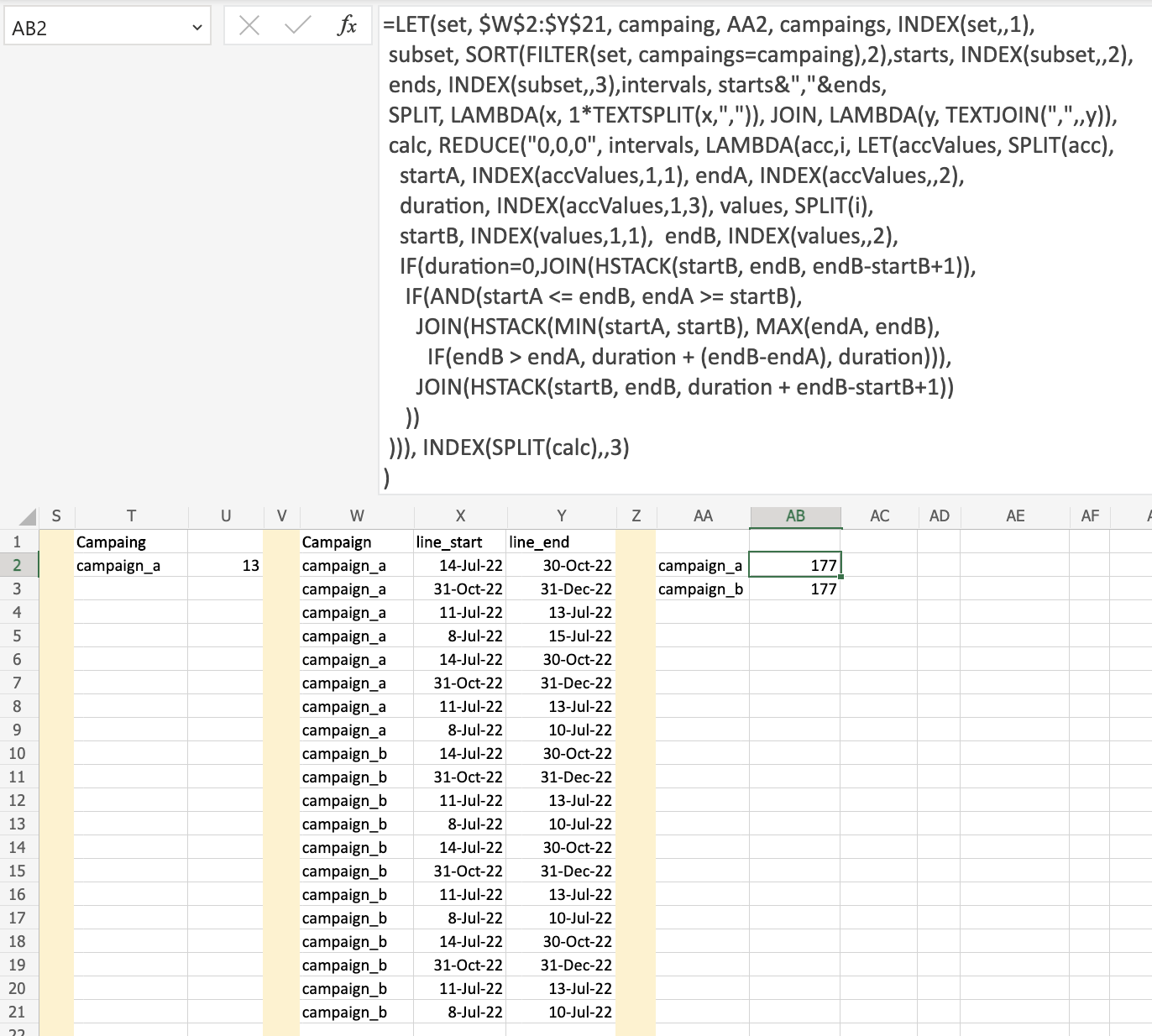
Basically, this problem is similar to calculating the project's total duration (in days). Where in this case each campaign's data can be assimilated as project tasks with start and end dates. The only difference here is that gaps don't contribute to project duration.
Let's illustrate it with the following example, since dates are represented in Excel as a positive integer, to simplify the calculation we can use just numbers as follow:

Grom the graph is easy to calculate that the total duration will be 13 days. Notice that the gap in columns K and P doesn't count for the total duration.
Based on this graphical representation we can build a logic for calculating the durations as we progress from the top of the Gantt chart to the bottom.
The logic to calculate the duration is based on identifying overlapping duration for each task. The condition to identify two intervals A,B overlap is the following:
AND(startA <= endB, endA >= startB)
we are going to iterate over all tasks and on each step update the new start and end dates and update the duration. Let's say we are going to calculate the new start and end dates for two consecutive rows represented by A and B intervals. The combined interval will be:
[MIN(startA, startB), MAX(endA, endB)]
If the previous duration is represented by the variable duration, then the updated duration will be:
IF(endB > endA, duration (endB - endA), duration)))
i.e, if the next interval (B) ends after A, then we need to update the duration with the difference (endB - endA).
If the intervals don't overlap, then the duration will be updated as follow:
duration = duration endB - startB 1
and the next start and end date will be the startB, endB for the next calculation.
The above process can now be put in Excel terms as follow:
=LET(set, $A$2:$C$21, campaing, E2, campaings, INDEX(set,,1),
subset, SORT(FILTER(set, campaings=campaing),2),starts, INDEX(subset,,2),
ends, INDEX(subset,,3),intervals, starts&","&ends,
SPLIT, LAMBDA(x, 1*TEXTSPLIT(x,",")), JOIN, LAMBDA(y, TEXTJOIN(",",,y)),
calc, REDUCE("0,0,0", intervals, LAMBDA(acc,i, LET(accValues, SPLIT(acc),
startA, INDEX(accValues,1,1), endA, INDEX(accValues,,2),
duration, INDEX(accValues,1,3), values, SPLIT(i),
startB, INDEX(values,1,1), endB, INDEX(values,,2),
IF(duration=0,JOIN(HSTACK(startB, endB, endB-startB 1)),
IF(AND(startA <= endB, endA >= startB),
JOIN(HSTACK(MIN(startA, startB), MAX(endA, endB),
IF(endB > endA, duration (endB-endA), duration))),
JOIN(HSTACK(startB, endB, duration endB-startB 1))
))
))), INDEX(SPLIT(calc),,3)
)
and here is the output:
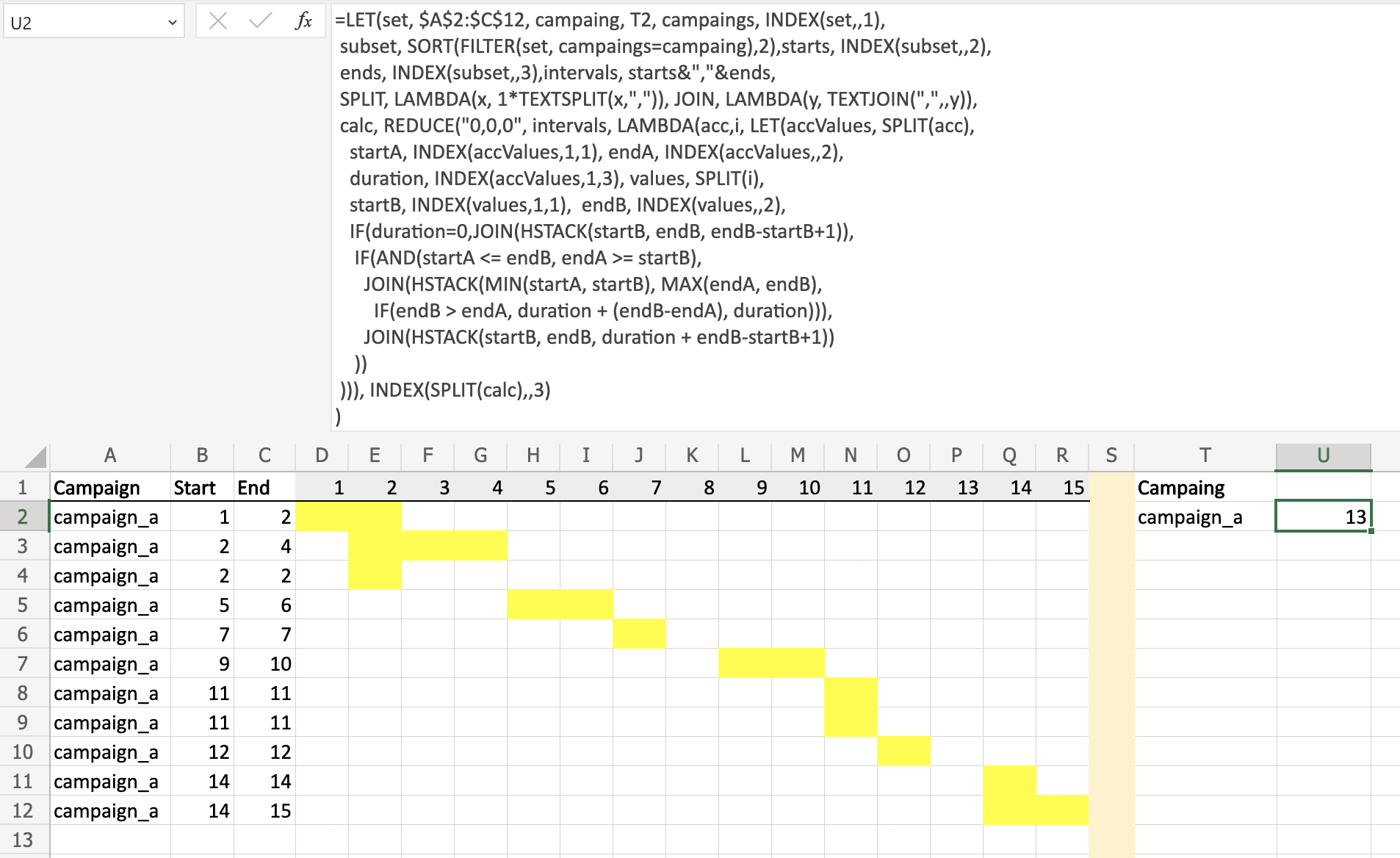
and here is the output for both campaigns based on the input data from the question: