I am using excel 2019 and I am trying to extract from a bunch of messed up text cells any (up to 5) word ending with dot that comes after a ].
This is a sample of the text I am trying to parse/clean `
some text [asred.] ost. |Monday - Ribben (ult.) lot. ac, sino. other maybe long text; collan.
`
I expect to get this:
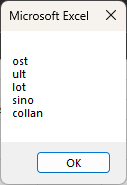
ost. ult. lot. sino. collan.
I am using this Function found somewhere on the internet which appears to do the job: `
Public Function RegExtract(Txt As String, Pattern As String) As String
With CreateObject("vbscript.regexp")
'.Global = True
.Pattern = Pattern
If .test(Txt) Then
RegExtract = .Execute(Txt)(0)
Else
RegExtract = "No match found"
End If
End With
End Function
`
and I call it from an empty cell:
=RegExtract(D2; "([\]])(\s\w [.]){0,5}")
It's the first time I am using regexp, so I might have done terrible things in the eyes of an expert.
So this is my expression: ([]])(\s\w [.]){0,5}
Right now it returns only
] ost.
Which is much more than I was expecting to be able to do on my first approach to regex, but:
- I am not able to get rid of the first ] which is needed to find the place where my useful bits start inside the text block, since \K does not work in excel. I might "find and replace" it later as a smart barbarian, but I'd like to know the way to do it clean, if any clean way exists :)
2)I don't understand how iterators work to get all my "up to 5 occurrencies": I was expecting that {0,5} after the second group meant exactly: "repeat the previous group again until the end of the text block (or until you manage to do it 5 times)".
Thank you for your time :)
CodePudding user response:
You can use the following regex
([a-zA-Z] ).
Let me explain a little bit.
[a-zA-Z] ----> this looks for anything that contain any letter from a to z and A to Z, but it only matches the first letter.
----> with this you are telling that matches all the letters until it finds something that is not a letter from a to z and A to Z
\. ----> with this you are just looking for the . at the end of the match
Here the