I have a dataframe where I have a date and a time column. Each row describes some event. I want to calculate the timespan for each different day and add it as new row. The actual calculation is not that important (which units etc.), I just want to know, how I can the first and last row for each date, to access the time value. The dataframe is already sorted by date and all rows of the same date are also ordered by the time.
Minimal example of what I have
import pandas as pd
df = pd.DataFrame({"Date": ["01.01.2020", "01.01.2020", "01.01.2020", "02.02.2022", "02.02.2022"],
"Time": ["12:00", "13:00", "14:45", "02:00", "08:00"]})
df
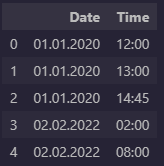
and what I want
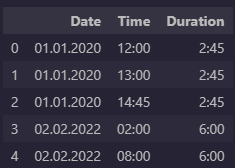
EDIT: The duration column should be calculated by 14:45 - 12:00 = 2:45 for the first date and 08:00 - 02:00 = 6:00 for the second date.
I suspect this is possible with the groupby function but I am not sure how exactly to do it.
CodePudding user response:
By the example shown below, you can achieve want you want.
df['Start time'] = df.apply(lambda row: df[df['Date'] == row['Date']]['Time'].max(), axis=1)
df
Update:
import datetime
df['Duration'] = df.apply(lambda row: str(datetime.timedelta(seconds=(datetime.datetime.strptime(df[df['Date'] == row['Date']]['Time'].max(), '%H:%M') - datetime.datetime.strptime(df[df['Date'] == row['Date']]['Time'].min(), '%H:%M')).total_seconds())) , axis=1)
df
CodePudding user response:
I hope you will find this helpful.
import pandas as pd
df = pd.DataFrame({"Date": ["01.01.2020", "01.01.2020", "01.01.2020", "02.02.2022", "02.02.2022"],
"Time": ["12:00", "13:00", "14:45", "02:00", "08:00"]})
df["Datetime"] = pd.to_datetime((df["Date"] " " df["Time"]))
def date_diff(df):
df["Duration"] = df["Datetime"].max() - df["Datetime"].min()
return df
df = df.groupby("Date").apply(date_diff)
df = df.drop("Datetime", axis=1)
Output:
Date Time Duration
0 01.01.2020 12:00 0 days 02:45:00
1 01.01.2020 13:00 0 days 02:45:00
2 01.01.2020 14:45 0 days 02:45:00
3 02.02.2022 02:00 0 days 06:00:00
4 02.02.2022 08:00 0 days 06:00:00
You can then do some string styling:
df['Duration'] = df['Duration'].astype(str).map(lambda x: x[7:12])
Output:
Date Time Duration
0 01.01.2020 12:00 02:45
1 01.01.2020 13:00 02:45
2 01.01.2020 14:45 02:45
3 02.02.2022 02:00 06:00
4 02.02.2022 08:00 06:00
CodePudding user response:
you can use:
from datetime import timedelta
import numpy as np
df['xdate']=pd.to_datetime(df['Date'] ' ' df['Time'],format='%d.%m.%Y %H:%M')
df['max']=df.groupby(df['xdate'].dt.date)['xdate'].transform(np.max) #get max dates each date
df['min']=df.groupby(df['xdate'].dt.date)['xdate'].transform(np.min) #get min date each date
#get difference max and min dates
df['Duration']= df[['min','max']].apply(lambda x: x['max'] - timedelta(hours=x['min'].hour,minutes=x['min'].minute,seconds=x['min'].second),axis=1).dt.strftime('%H:%M')
df=df.drop(['xdate','min','max'],axis=1)
print(df)
'''
Date Time Duration
0 01.01.2020 12:00 02:45
1 01.01.2020 13:00 02:45
2 01.01.2020 14:45 02:45
3 02.02.2022 02:00 06:00
4 02.02.2022 08:00 06:00
'''
CodePudding user response:
here is one way to do it
# groupby on Date and find the difference of max and min time in each group
# format it as HH:MM by extracting Hours and minutes
# and creating a dictionary
d=dict((df.groupby('Date')['Time'].apply(lambda x:
(pd.to_timedelta(x.max() ':00') -
pd.to_timedelta(x.min() ':00')
)
).astype(str).str.extract(r'days (..:..)')
).reset_index().values)
# map the dictionary and update the duration in DF
df['duration']=df['Date'].map(d)
df
Date Time duration
0 01.01.2020 12:00 02:45
1 01.01.2020 13:00 02:45
2 01.01.2020 14:45 02:45
3 02.02.2022 02:00 06:00
4 02.02.2022 08:00 06:00