I have a pandas dataframe, with two columns id and user_name.
Where the id column have this format (xxxxxx-xxx-A): r'[0-9]{6}-[0-9]{3}$' alphabet letter.
Here's my dataframe example :
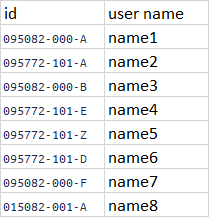
The expected result is to keep only the rows with the id that the part "xxxxxx-xxx-" not duplicate and with the last (by order) alphabet letter:
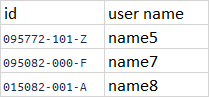
What is the efficient way to do it? Thank you
CodePudding user response:
You can split your string in the common identifier and the letter, then sort the values in the desired priority, finally get the last index per group:
idx = (df['id']
.str.extract(r'([0-9]{6}-[0-9]{3})-(.*)')
.sort_values(by=1)
.reset_index()
.groupby(0, sort=False)['index'].last()
)
out = df.loc[idx]
output
id user_name
0 095082-000-P name1
4 095772-101-Z name5
7 015082-001-P name8
CodePudding user response:
df = pd.DataFrame({'id': ['095082-000-A', '095772-101-A', '095082-000-B', '095772-101-E', '095772-101-Z',
'095772-101-D', '095082-000-F', '015082-001-A'],
'user name': ['name1', 'name2', 'name3', 'name4', 'name5', 'name6', 'name7', 'name8']})
df = (df.groupby(df.id.str.slice(0, 10)).agg({'id': max})
.reset_index(drop=True).merge(df, on='id')
.sort_values('user name').reset_index(drop=True))
print(df)
id user name
0 095772-101-Z name5
1 095082-000-F name7
2 015082-001-A name8