I have the following data which I am using to plot a Kaplan Meier curve using this code:
fit <- survfit(Surv(time_to_first_g3_tox, grade_3_tox_bool) ~ tx_start_schedule, data = df)
ggsurvplot(fit, risk.table = TRUE, surv.median.line = "hv")
This is going all the way up to 1200 days, but I would like the plot and the table to stop at 90 days. Is this possible? Thanks
Dataframe below:
#> dput(df)
structure(list(id = c("1001", "1002", "1003", "1004", "1005",
"1006", "1007", "1008", "1009", "1010", "1011", "1013", "1014",
"1015", "1016", "1017", "1018", "1019", "1020", "1021", "1022",
"1023", "1024", "1025", "1026", "1027", "1028", "1029", "1030",
"1031", "1032", "1034", "1035", "1036", "1037", "1038", "1039",
"1040", "1041", "1042", "1043", "1044", "1045", "1046", "1047",
"1012", "1301", "1302", "1303", "1304", "1305", "1306", "1307",
"1308", "1309", "1310", "1311", "1312", "1313", "1314", "1315",
"1101", "1102", "1103", "1104", "1105", "1106", "1107", "1108",
"1109", "1110", "1111", "1112", "1113", "1114", "1115", "1116",
"1117", "1118", "1119", "1120", "1201", "1202", "1203", "1204",
"1205", "1206", "1207", "1208", "1209", "1210", "1211", "1212",
"1213", "1214", "1215", "1216", "1217", "1218", "1219", "1220",
"1221", "1222", "1223", "1224", "1225", "1226", "1227", "1228",
"1229", "1230", "1231", "1232", "1233", "1234", "1235", "1236",
"1237", "1238", "1239", "1240", "1241", "1242", "1243", "1244",
"1245", "1246", "1247", "1248", "1249", "1250", "1251", "1252",
"1253", "1254", "1255", "1256", "1257", "1258", "1259", "1260",
"1401", "1402", "1403", "1404", "1405", "1406", "1407", "1408",
"1409", "1410", "1411", "1412", "1413", "1414", "1415", "1416",
"1417", "1418", "1419", "1420", "1421", "1422", "1423", "1424",
"1425", "1426", "1427", "1428", "1429", "1430", "1431", "1432",
"1433", "1434", "1435", "1436", "1501", "1502", "1503", "1504",
"1505", "1506", "1507", "1508", "1509", "1510", "1511", "1512",
"1513", "1514", "1515", "1516", "1517", "1518", "1519", "1520",
"1521", "1522", "1523", "1524", "1525", "1526", "1527", "1528",
"1529", "1530", "1531", "1532", "1533", "1534", "1535", "1536",
"1537", "1538", "1539", "1540", "1541", "1542", "1543", "1544",
"1545", "1546", "1547", "1548", "1549", "1550", "1551", "1552",
"1553", "1554", "1555", "1556", "1557", "1558", "1559", "1560",
"1561", "1562", "1563", "1564", "1565", "1566", "1567", "1568",
"1569", "1570", "1571", "1701", "1702", "1703", "1704", "1705",
"1706", "1707", "1708", "1709", "1710", "1711", "1712", "1713",
"1714", "1715", "1716", "1601", "1602", "1603", "1604", "1605",
"1606", "1607", "1608", "1609", "1610", "1611", "1612", "1613",
"1614", "1615", "1616", "1617", "1618", "1619", "1620", "1621",
"1622", "1623", "1624", "1625", "1626", "1627", "1628", "1629",
"1630", "1631", "1632", "1633", "1634", "1635", "1636", "1637",
"1638", "1639", "1640", "1641", "1642", "1643", "1644", "1645",
"1646", "1647", "1648", "1649", "1650"), tx_start_schedule = structure(c(1L,
2L, 2L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 1L, 2L, 2L, 2L, 1L, 2L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
2L, 2L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 1L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
2L, 1L, 2L, 2L, 1L, 2L, 1L, 2L, 2L, 1L, 2L, 2L, 2L, 1L, 2L, 2L,
1L, 2L, 2L, 2L, 2L, 2L, 2L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 1L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 1L, 2L, 1L, 2L, 2L, 2L, 2L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 2L, 2L, 2L, 2L, 2L, 1L, 2L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 1L, 2L, 2L, 1L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 2L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 1L,
2L, 2L, 1L, 1L, 2L, 2L, 2L, 2L, 1L, 2L, 2L, 2L, 2L, 1L, 2L, 2L,
2L, 2L, 2L, 2L, 1L, 1L, 2L, 2L, 2L), .Label = c("Q3W", "Q6W"), class = "factor"),
grade_3_tox_bool = c(FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE,
FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, TRUE,
FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE, TRUE,
FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE,
FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, TRUE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE,
FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE,
FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, FALSE,
TRUE, TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, TRUE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE,
FALSE, FALSE), time_to_first_g3_tox = structure(c(452, 439,
412, 573, 456, 475, 108, 273, 350, 486, 100, 249, 316, 326,
341, 292, 321, 396, 78, 488, 287, 87, 447, 502, 408, 316,
270, 83, 671, 321, 190, 882, 478, 383, 571, 27, 655, 71,
861, 950, 58, 592, 648, 637, 3, 516, 664, 650, 649, 294,
608, 609, 609, 606, 593, 339, 251, 565, 587, 258, 1071, 331,
66, 206, 141, 292, 126, 369, 308, 699, 863, 805, 512, 585,
518, 531, 33, 317, 339, 563, 547, 658, 322, 518, 152, 155,
313, 32, 518, 376, 616, 448, 643, 272, 521, 191, 45, 750,
624, 583, 679, 659, 650, 620, 728, 497, 599, 671, 649, 194,
665, 518, 672, 453, 14, 622, 607, 164, 597, 625, 413, 640,
75, 450, 541, 527, 543, 678, 189, 637, 693, 694, 735, 742,
714, 585, 714, 553, 663, 577, 752, 425, 346, 286, 577, 279,
29, 479, 437, 465, 623, 713, 139, 159, 646, 29, 158, 27,
21, 135, 405, 842, 0, 235, 726, 577, 444, 510, 520, 591,
1149, 189, 800, 625, 639, 317, 158, 167, 157, 1195, 209,
1144, 0, 123, 1058, 1022, 1011, 983, 69, 469, 934, 906, 879,
882, 17, 85, 847, 819, 813, 812, 805, 55, 797, 783, 776,
776, 584, 111, 30, 714, 705, 691, 298, 672, 644, 6, 598,
556, 556, 544, 545, 531, 532, 511, 511, 504, 510, 503, 489,
45, 291, 132, 461, 454, 447, 125, 440, 7, 434, 427, 41, 83,
412, 10, 392, 384, 384, 377, 862, 860, 757, 677, 163, 636,
839, 791, 784, 618, 657, 590, 443, 580, 556, 39, 248, 909,
908, 908, 905, 899, 897, 902, 898, 898, 875, 870, 866, 859,
132, 849, 139, 847, 109, 43, 814, 100, 799, 798, 791, 790,
779, 770, 763, 762, 762, 758, 757, 321, 749, 749, 33, 744,
111, 727, 260, 720, 713, 48, 168, 210, 701, 699, 694, 406
), class = "difftime", units = "days")), row.names = c(NA,
-314L), class = c("tbl_df", "tbl", "data.frame"))
CodePudding user response:
You could use xlim with break.x.by to control the breaks like this:
library(survival)
library(survminer)
fit <- survfit(Surv(time_to_first_g3_tox, grade_3_tox_bool) ~ tx_start_schedule, data = df)
ggsurvplot(fit, risk.table = TRUE, surv.median.line = "hv", break.x.by = c(10), xlim = c(0, 90))
#> Warning in .add_surv_median(p, fit, type = surv.median.line, fun = fun, : Median
#> survival not reached.
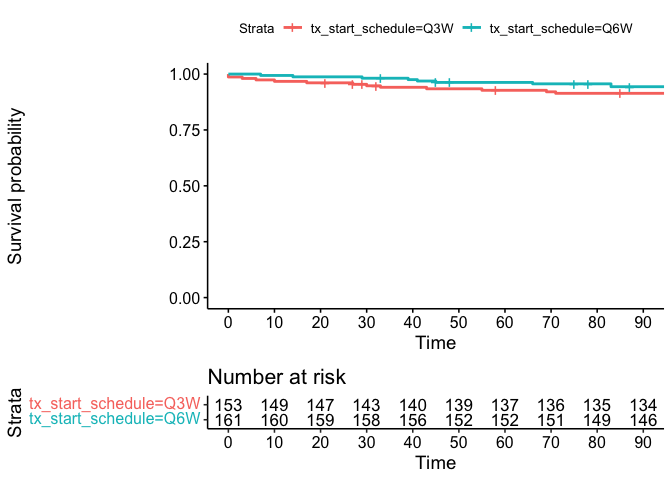
Created on 2022-11-16 with reprex v2.0.2
Check documentation for more information.