I have a pod with a cron job container and a never ending container.
is there a way to mark the pod as successfull when the cron job ends?
The problem is that with the never ending container in the same pod of the cron job the pod remains always in active status and I'd like to terminate it with success. There was a faliure in a node and when restarting it the cron job has started two times in the same days and I want to also avoid this.
I found a solution with activeDeadlinesSeconds but with this porperty the pod goes in failed status as read on the docs.
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
concurrencyPolicy: Replace
jobTemplate:
spec:
ttlSecondsAfterFinished: 30
activeDeadlineSeconds: 10
template:
spec:
hostAliases:
- ip: "192.168.59.1"
hostnames:
- "host.minikube.internal"
containers:
- name: webapp1
image: katacoda/docker-http-server:latest
ports:
- containerPort: 80
- name: hello
image: quarkus-test
imagePullPolicy: Never
command: ["./application", "-Dquarkus.http.host=0.0.0.0"]
restartPolicy: OnFailure
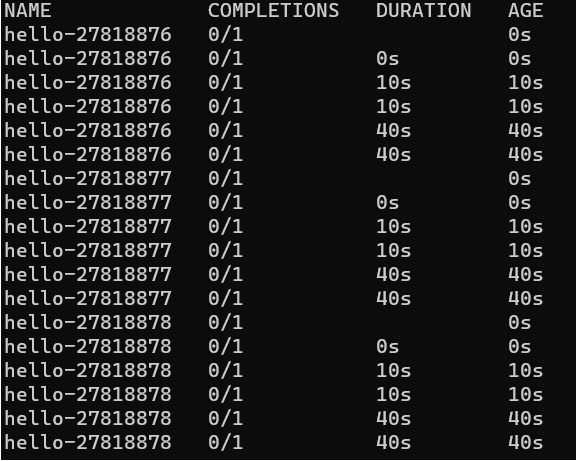
As you can see in this image the pod start, after 10 seconds with activeDeadlineSeconds the pod is putted in failed status, and other after 30 seconds with ttlSecondsAfterFinished the pod is deleted.

As you can see here the cron job is putted from active 1 to active 0.
If I don't use activeDeadlineSeconds the cron job remains always active.
I've read about a solution using volumes between the two containers and writing a file when the cron job ends but I canno't touch the never ending code/container is not under my control.
CodePudding user response:
You can use a shared volume, write a file there when your job ends and use a livenessprobe on your never ending container to test if the file does not exist. From the moment the job creates the file the livenessprobe will fail and your never ending container should stop. Here an example where the nginx container stops when the file /cache/stop is created in the shared volume
apiVersion: batch/v1
kind: Job
metadata:
name: multicontainer-job
spec:
template:
spec:
containers:
- name: busy
image: busybox
imagePullPolicy: IfNotPresent
command:
- sh
- -c
args:
- echo start > /cache/start; sleep 30; echo stop > /cache/stop;
volumeMounts:
- mountPath: /cache
name: cache-volume
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /cache
name: cache-volume
livenessProbe:
exec:
command:
- sh
- -c
- if test -f "/cache/stop"; then exit 1; fi;
initialDelaySeconds: 5
periodSeconds: 5
restartPolicy: Never
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi
backoffLimit: 4