According to
Attention is all you needpaper: Additive attention (The classic attention use in RNN by Bahdanau) computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, ...
Indeed, we can see 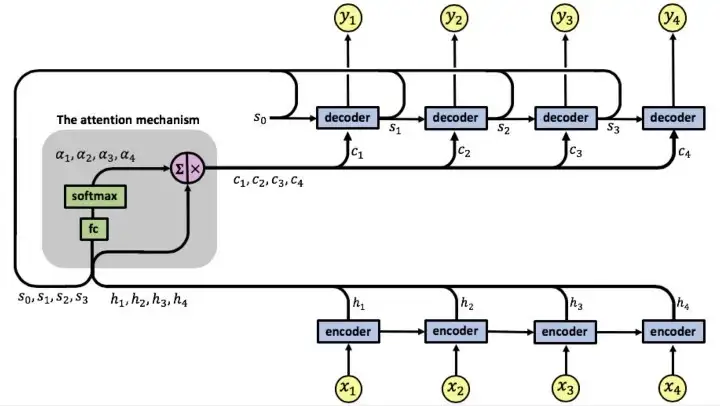
Figure 1: Attention mechanism diagram from [2].
Thus, the alignment scores are calculated by adding the outputs of the decoder hidden state to the encoder outputs. So the additive attention is not a RNN cell.
References
[1] Bahdanau, D., Cho, K. and Bengio, Y., 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[2] Arbel, N., 2019. Attention in RNNs. Medium blog post.