The solutions I found online only show removing outliers from the entire dataframe, not just a specific column. So I'm having trouble figuring out how to perform outlier removal on a single column.
I tried creating a method, the code is shown below.
def find_outlier(df, column):
# Find first and third quartile
q1 = df[column].quantile(0.25)
q3 = df[column].quantile(0.75)
# Find interquartile range
IQR = q3 - q1
# Find lower and upper bound
lower_bound = q1 - 1.5 * IQR
upper_bound = q3 1.5 * IQR
# Remove outliers
df[column] = df[column][df[column] > lower_bound]
df[column] = df[column][df[column] < upper_bound]
return df
But when I ran the code, it said "Columns must be same length as key".
The code I used to run is shown below.
df['no_of_trainings'] = find_outlier(df, 'no_of_trainings')
Any help is appreciated.
CodePudding user response:
The comparison result is by-index, so you can use it to reduce the DataFrame
df = df[df[column] > lower_bound]
df = df[df[column] < upper_bound]
return df
more concisely
...
return df[(df[column] > lower_bound) & (df[column] < upper_bound)]
CodePudding user response:
There is no problem with your find_outlier code except for the return statement:
Should be
return df[column]
You code will replace outliers with NaN values.
Example code:
import pandas as pd
def find_outlier(df, column):
# Find first and third quartile
q1 = df[column].quantile(0.25)
q3 = df[column].quantile(0.75)
# Find interquartile range
IQR = q3 - q1
# Find lower and upper bound
lower_bound = q1 - 1.5 * IQR
upper_bound = q3 1.5 * IQR
# Remove outliers
df[column] = df[column][df[column] > lower_bound]
df[column] = df[column][df[column] < upper_bound]
return df[column]
df1 = pd.DataFrame({'no_of_trainings':[1,2,3,4,5,1000,6,7,8,9,10],
'other_data':[1,2,3,4,5,9,6,7,8,9,10]})
df1['no_of_trainings'] = find_outlier(df1, 'no_of_trainings')
print(df1)
Output:
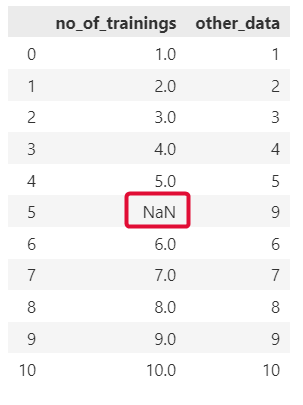
Note:
The outlier of 1000 was removed.