I have a data that looks like :
df = pd.DataFrame({
'ID': [1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2],
'DATE': ['1/1/2015','1/2/2015', '1/3/2015','1/4/2015','1/5/2015','1/6/2015','1/7/2015','1/8/2015',
'1/9/2016','1/2/2015','1/3/2015','1/4/2015','1/5/2015','1/6/2015','1/7/2015'],
'CD': ['A','A','A','A','B','B','A','A','C','A','A','A','A','A','A']})
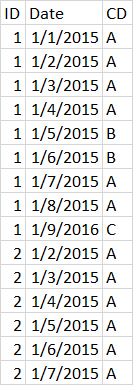
I would like to count # of changes that occurs by ID and CD. How can I get the desired result. When I tried cumcount, it will count same groupby and give it different numbers.
What I get is :
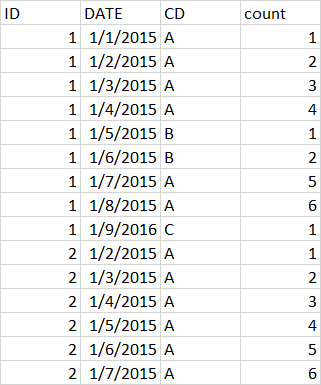
What I am expecting is :
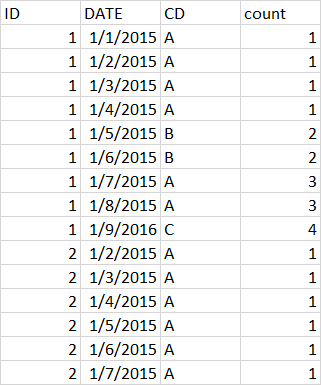
CodePudding user response:
Lets group on ID column and use shift on CD to check for changes then use cumsum to create sequential counter
df['count'] = df.groupby('ID')['CD'].apply(lambda s: s.ne(s.shift()).cumsum())
Result
ID DATE CD count
0 1 1/1/2015 A 1
1 1 1/2/2015 A 1
2 1 1/3/2015 A 1
3 1 1/4/2015 A 1
4 1 1/5/2015 B 2
5 1 1/6/2015 B 2
6 1 1/7/2015 A 3
7 1 1/8/2015 A 3
8 1 1/9/2016 C 4
9 2 1/2/2015 A 1
10 2 1/3/2015 A 1
11 2 1/4/2015 A 1
12 2 1/5/2015 A 1
13 2 1/6/2015 A 1
14 2 1/7/2015 A 1
CodePudding user response:
your count column in desired output means group
First
make grouper to divide group (changed bool to int for ease of viewing)
col = ['ID', 'CD']
grouper = df[col].ne(df[col].shift(1)).any(axis=1).astype('int')
grouper
0 1
1 0
2 0
3 0
4 1
5 0
6 1
7 0
8 1
9 1
10 0
11 0
12 0
13 0
14 0
dtype: int32
Second
divide group in same ID (I made grouper to count column because had to create count column anyway.)
df.assign(count=grouper).groupby('ID')['count'].cumsum()
output:
0 1
1 1
2 1
3 1
4 2
5 2
6 3
7 3
8 4
9 1
10 1
11 1
12 1
13 1
14 1
Name: count, dtype: int32
Last
make output to count column
df.assign(count=df.assign(count=grouper).groupby('ID')['count'].cumsum())
result:
ID DATE CD count
0 1 1/1/2015 A 1
1 1 1/2/2015 A 1
2 1 1/3/2015 A 1
3 1 1/4/2015 A 1
4 1 1/5/2015 B 2
5 1 1/6/2015 B 2
6 1 1/7/2015 A 3
7 1 1/8/2015 A 3
8 1 1/9/2016 C 4
9 2 1/2/2015 A 1
10 2 1/3/2015 A 1
11 2 1/4/2015 A 1
12 2 1/5/2015 A 1
13 2 1/6/2015 A 1
14 2 1/7/2015 A 1
Update full code
more simple full code with advice of @cottontail
col = ['ID', 'CD']
grouper = df[col].ne(df[col].shift(1)).any(axis=1).astype('int')
df.assign(count=grouper.groupby(df['ID']).cumsum())