I have a list of Customer Names and Supplier Names and since of 2 different countries in the same company. Unfortunately same Customer and Suppliers have different ids in different countries. In the other hand the names in the most of the cases are the same or at least very similar.
The goal is to have a PBI report with unified customers/suppliers for both countries.
So I will try to match them by name.
But I want in someway to check for possible same names which have a very small difference like a letter for example i found the Greek name "HARALAMPOS" in the one Country and "CHARALAMPOS" in the other.
I am pretty sure that I can do this in python but I have no idea how. What I want is to extract a list with the Names of the countries (actually it is not only 2 are 8). and find the most similar cases like the example I gave above.
Can anyone navigate me of which libraries I need to use and which packages from each library in order to achieve that ?
I have these 3 columns in different schemas in SQL tables and if you noticed there are some differences for example in Germany the L.T.D. contains dots or for the Customer Name "Hermanos" in Germany is "LOS HERMANOS". This is because of the users that they added the data but is the only possible way to match them for me.
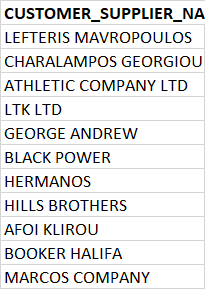
GREECE DATA
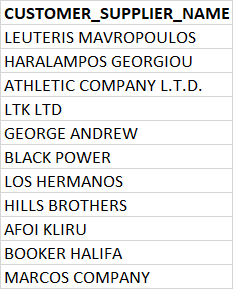
GERMANY DATA:
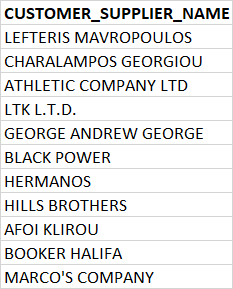
US DATA:
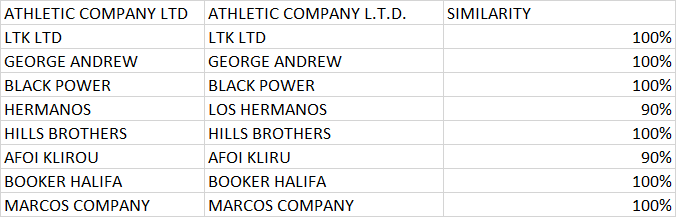
Expected Result
CodePudding user response:
IIUC, you can use rapidfuzz and pandas.DataFrame.merge.
To give you the general logic, let's compare for example two dataframes (df_ger) with (df_us) :
import pandas as pd
from rapidfuzz import process
out = (
df_ger
.assign(message_adapted = (df_ger['CUSTOMER_SUPPLIER_NAME']
.map(lambda x: process.extractOne(x, df_us['CUSTOMER_SUPPLIER_NAME']))).str[0])
.merge(df_us.add_suffix(" (US)"),
left_on="message_adapted", right_on="CUSTOMER_SUPPLIER_NAME (US)", how="left", indicator="CHECK")
.rename(columns= {"CUSTOMER_SUPPLIER_NAME": "CUSTOMER_SUPPLIER_NAME (GE)"})
.drop(columns="message_adapted")
)
# Output :
print(out)
CUSTOMER_SUPPLIER_NAME (GE) CUSTOMER_SUPPLIER_NAME (US) CHECK
0 LEUTERIS MAVROPOULOS LEFTERIS MAVROPOULOS both
1 HARALAMPOS GEORGIOU CHARALAMPOS GEORGIOU both
2 ATHLETIC COMPANY L.T.D. ATHLETIC COMAPANY LTD both
3 LTK LTD LTK L.T.D. both
4 GEORGE ANDREW GEORGE ANDREW GEORGE both
5 BLACK POWER BLACK POWER both
6 LOS HERMANOS HERMANOS both
7 HILLS BROTHERS HILLS BROTHERS both
8 AFOI KLIRU AFOI KLIROU both
9 BOOKER HALIFA BOOKER HALIFA both
10 MARCOS COMPANY MARCO'S COMPANY both
# Edit :
Assuming, you have a single dataframe df holding two columns and you want to calculate the score of similarity between those, you can use difflib.SequenceMatcher :
from difflib import SequenceMatcher
df['SIMILARITY'] = (
df.apply(lambda x: str(round(SequenceMatcher(None,
x[0].lower(),
x[1].lower()).ratio(),2)*100) "%",
axis=1)
)
print(df)
CUSTOMER_SUPPLIER_NAME (GE) CUSTOMER_SUPPLIER_NAME (US) SIMILARITY
0 LEUTERIS MAVROPOULOS LEFTERIS MAVROPOULOS 95.0%
1 HARALAMPOS GEORGIOU CHARALAMPOS GEORGIOU 97.0%
2 ATHLETIC COMPANY L.T.D. ATHLETIC COMAPANY LTD 91.0%
3 LTK LTD LTK L.T.D. 82.0%
4 GEORGE ANDREW GEORGE ANDREW GEORGE 79.0%
5 BLACK POWER BLACK POWER 100.0%
6 LOS HERMANOS HERMANOS 80.0%
7 HILLS BROTHERS HILLS BROTHERS 100.0%
8 AFOI KLIRU AFOI KLIROU 95.0%
9 BOOKER HALIFA BOOKER HALIFA 100.0%
10 MARCOS COMPANY MARCO'S COMPANY 97.0%