Here's the dataset I'm dealing with (called depo_dataset):
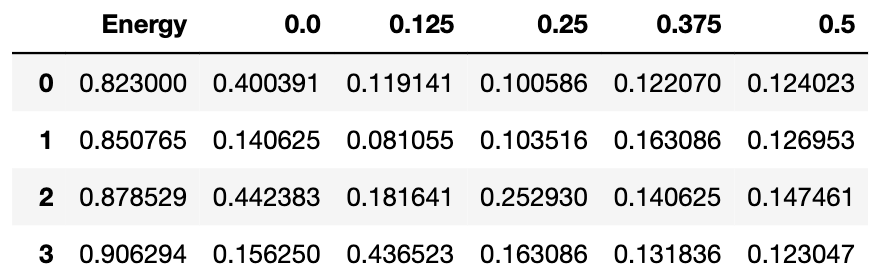 Some entries starting from the second column (0.0) might be 0.000..., the goal is for each column starting from the 2nd one, I will generate a separate array of
Some entries starting from the second column (0.0) might be 0.000..., the goal is for each column starting from the 2nd one, I will generate a separate array of Energy, with the 0.0... entry in the column and associated Energy removed. I'm trying to use a mask in pandas. Here's what I tried:
for column in depo_dataset.columns[1:]:
e = depo_dataset['Energy'].copy()
mask = depo_dataset[column] == 0
Then I don't know how can I drop the 0 entry (assume there is one), and the corresponding element is e?
For instance, suppose we have depo_dataset['0.0'] to be 0.4, 0.0, 0.4, 0.1, and depo_dataset['Energy'] is 0.82, 0.85, 0.87, 0.90, I hope to drop the 0.0 entry in depo_dataset['0.0'], and 0.85 in depo_dataset['Energy'] .
Thanks for the help!
CodePudding user response:
You can just us .loc on the DataFrame to filter out some rows.
Here a little example:
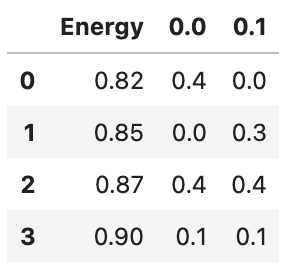
df = pd.DataFrame({
'Energy': [0.82, 0.85, 0.87, 0.90],
0.0: [0.4, 0.0, 0.4, 0.1],
0.1: [0.0, 0.3, 0.4, 0.1]
})
energies = {}
for column in df.columns[1:]:
energies[column] = df.loc[df[column] != 0, ['Energy', column]]
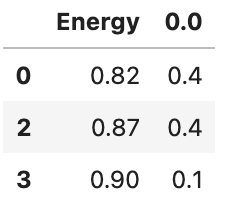
energies[0.0]
CodePudding user response:
you can use .loc:
depo_dataset = pd.DataFrame({'Energy':[0.82, 0.85, 0.87, 0.90],
'0.0':[0.4, 0.0, 0.4, 0.1],
'0.1':[1,2,3,4]})
dataset_no_zeroes = depo_dataset.loc[(depo_dataset.iloc[:,1:] !=0).all(axis=1),:]
Explanation:
(depo_dataset.iloc[:,1:] !=0)
makes a dataframe from all cols beginning with the second one with bool values indicating if the cell is zero.
.all(axis=1)
take the rows of the dataframe '(axis =1)' and only return true if all values of the row are true