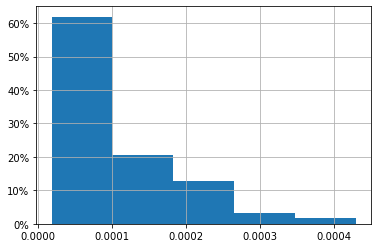
I first try to draw my data as percentage as follows:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.ticker import PercentFormatter
plt.hist(data, weights=np.ones(len(data)) / len(data), bins=5)
plt.gca().yaxis.set_major_formatter(PercentFormatter(1))
plt.grid()
plt.show()
This will give me this.
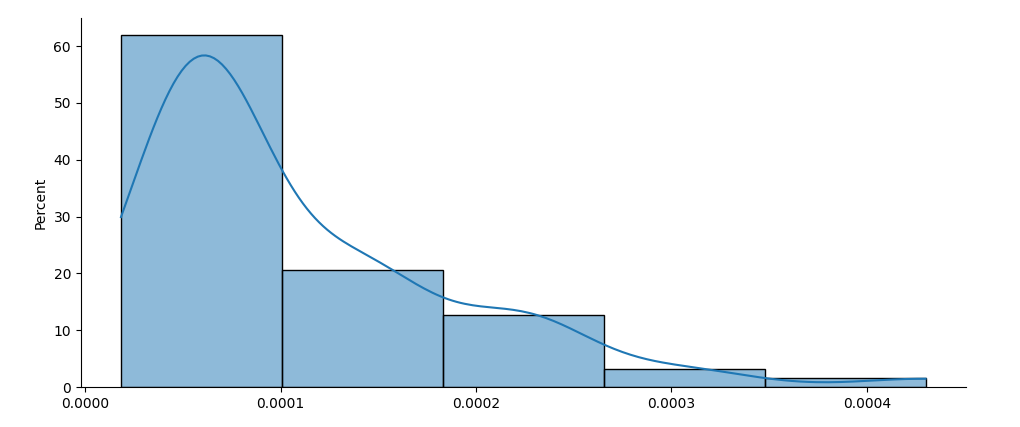
Now I used this line to fit a curve on the "percentage data" as follows :
import seaborn as sns
p=sns.displot(data=data, x="Dist",kde=True, bins=5)
Which gives me this:
But this curve was fitted according to the data not the percent per 5 bins. If for example you had 10 bins you could understand why there was a bump at the end. That bump we don't want to see. What I really want is a curve as this
CodePudding user response:
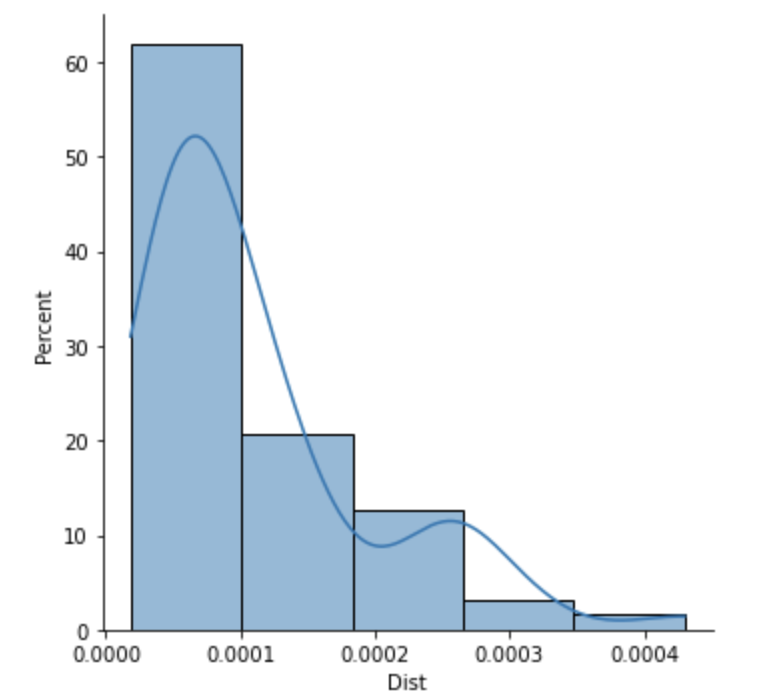
The kde plot approximates the data as a sum of guassian bell curves. An idea could be to regroup the data and place them at the centers of each bar.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
z = [1.83E-05,2.03E-05,3.19E-05,3.39E-05,3.46E-05,3.56E-05,3.63E-05,3.66E-05,4.13E-05,4.29E-05,4.29E-05,4.79E-05,5.01E-05,5.07E-05,5.08E-05,5.21E-05,5.39E-05,5.75E-05,5.91E-05,5.95E-05,5.98E-05,6.00E-05,6.40E-05,6.41E-05,6.67E-05,6.79E-05,6.79E-05,6.92E-05,7.03E-05,7.17E-05,7.45E-05,7.75E-05,7.99E-05,8.03E-05,8.31E-05,8.74E-05,9.69E-05,9.80E-05,9.86E-05,0.000108267,0.000108961,0.000109634,0.000111083,0.000111933,0.00011491,0.000126831,0.000135493,0.000138174,0.000141792,0.000150507,0.000155346,0.000155516,0.000202407,0.000243149,0.000248106,0.00025259,0.000254496,0.000258372,0.000258929,0.000265318,0.000293665,0.000312719,0.000430077]
counts, bin_edges = np.histogram(z, 5)
centers = (bin_edges[:-1] bin_edges[1:]) / 2
regrouped_data = np.repeat(centers, counts)
sns.histplot(data=regrouped_data, kde=True, bins=bin_edges)
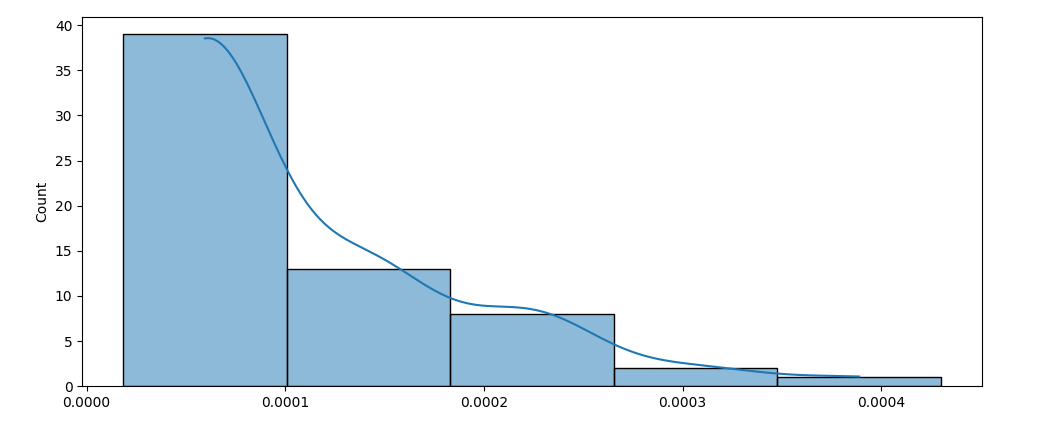
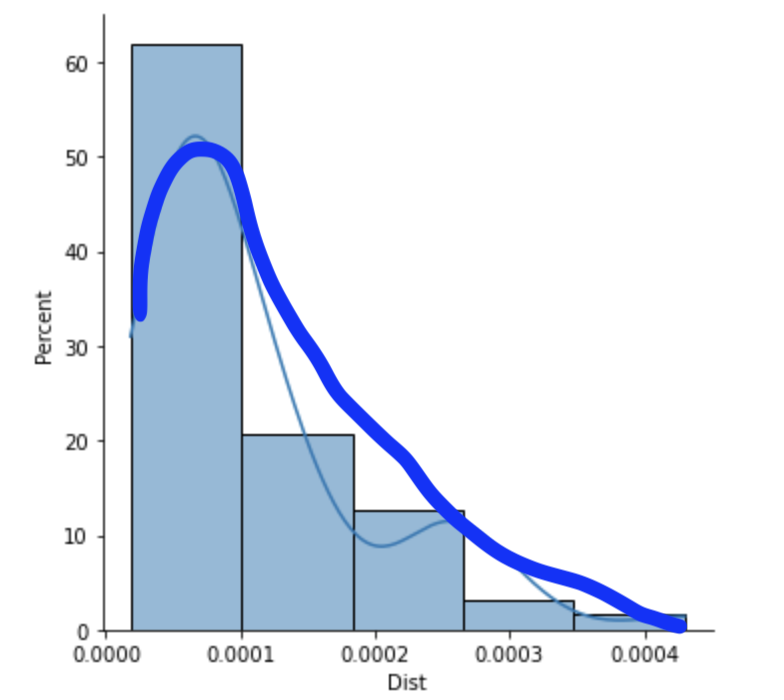
Normally, a kdeplot can be extended via the clip= parameter, but unfortunately kde_kws={'clip':bin_edges[[0,-1]]} doesn't work here.
To extend the kde, a trick could be to keep the highest and lowest value of the original data. So, subtracting one of the counts of the first and last bin, and append the lowest and highest value to the regrouped data.
counts, bin_edges = np.histogram(z, 5)
centers = (bin_edges[:-1] bin_edges[1:]) / 2
counts[[0, -1]] -= 1
regrouped_data = np.concatenate([np.repeat(centers, counts), bin_edges[[0, -1]]])
sns.histplot(data=regrouped_data, kde=True, bins=bin_edges, stat='percent')