Sample Table:
create table sampledata as
select 78328696 pkid, 12848815 customer_id, to_date('10/19/2022 11:05:38 AM','MM/DD/YYYY HH:MI:SS AM') actdate, 0.5 units, to_timestamp('19-OCT-22 11.05.38.947750000 AM') datetime from dual
union all
select 78328697, 12848815, to_date('10/19/2022 11:05:39 AM','MM/DD/YYYY HH:MI:SS AM'), 0.5, to_timestamp('19-OCT-22 11.05.39.024819000 AM') from dual
union all
select 78328698, 12848815, to_date('10/19/2022 11:05:39 AM','MM/DD/YYYY HH:MI:SS AM'), 0.5, to_timestamp('19-OCT-22 11.05.39.050859000 AM') from dual
union all
select 78321196, 12978419, to_date('10/19/2022 9:13:56 AM','MM/DD/YYYY HH:MI:SS AM'), 1, to_timestamp('19-OCT-22 09.13.56.879037000 AM') from dual
union all
select 78321197, 12978419, to_date('10/19/2022 9:13:56 AM','MM/DD/YYYY HH:MI:SS AM'), 1, to_timestamp('19-OCT-22 09.13.56.909837000 AM') from dual
union all
select 78321199, 12978419, to_date('10/19/2022 9:13:56 AM','MM/DD/YYYY HH:MI:SS AM'), 1, to_timestamp('19-OCT-22 09.13.56.931040000 AM') from dual
union all
select 78321200, 12978419, to_date('10/19/2022 9:13:56 AM','MM/DD/YYYY HH:MI:SS AM'), 1, to_timestamp('19-OCT-22 09.13.56.952084000 AM') from dual
union all
select 78321201, 12978419, to_date('10/19/2022 9:13:56 AM','MM/DD/YYYY HH:MI:SS AM'), 1, to_timestamp('19-OCT-22 09.13.56.971703000 AM') from dual
union all
select 78321202, 12978419, to_date('10/19/2022 9:13:56 AM','MM/DD/YYYY HH:MI:SS AM'), 1, to_timestamp('19-OCT-22 09.13.56.993092000 AM') from dual
union all
select 78321203, 12978419, to_date('10/19/2022 9:13:57 AM','MM/DD/YYYY HH:MI:SS AM'), 1, to_timestamp('19-OCT-22 09.13.57.014174000 AM') from dual
union all
select 78330838, 13710675, to_date('10/19/2022 11:44:29 AM','MM/DD/YYYY HH:MI:SS AM'), 0.5, to_timestamp('19-OCT-22 11.44.29.465212000 AM') from dual
union all
select 78330839, 13710675, to_date('10/19/2022 11:44:29 AM','MM/DD/YYYY HH:MI:SS AM'), 0.5, to_timestamp('19-OCT-22 11.44.29.498326000 AM') from dual
union all
select 78330840, 13710675, to_date('10/19/2022 11:44:29 AM','MM/DD/YYYY HH:MI:SS AM'), 0.5, to_timestamp('19-OCT-22 11.44.29.527076000 AM') from dual
union all
select 78331625, 13710675, to_date('10/19/2022 11:56:28 AM','MM/DD/YYYY HH:MI:SS AM'), 0.5, to_timestamp('19-OCT-22 11.56.28.726815000 AM') from dual
I am looking to aggregate transactions together and sum the units. However, they need to be in the same transaction and there is nothing that specifically denotes a transaction. They will all have an ACTDATE within 1 or perhaps 2 seconds. So I am looking to group the first 3 rows together based on CUSTOMER_ID and sum the units. The next 7 rows would be grouped together as one transaction as well. The tricky part is when I hit the last 4 rows, CUSTOMER_ID 13710675. Here, there are actually 2 transactions. One transaction consisting of 3 rows at 11:44 and then a single row transaction at 11:56.
I have considered doing a lead(ACTDATE) over(partition by..., and look at the time difference, but this gets convoluted as well as resource and execution time heavy considering the number of rows in the actual data. I looked at rounding the microseconds in order to get the ACTDATE to match and include it in the GROUP BY, but this sacrifices some accuracy, including in the example given. Can you recommend an easier method? Please notice that the PKID may skip a number. I will take the max(PKID) and the trunc(ACTDATE) so the output should be:
CodePudding user response:
On recent versions of Oracle - since Oracle 12c - you can use match_recognize to do this:
select max(pkid) as pkid,
customer_id,
trunc(max(actdate)) as accdate,
sum(units) as units
from sampledata
match_recognize (
partition by customer_id
order by actdate
measures match_number() as match_num
all rows per match
pattern (start_tran same_tran*)
define same_tran as (actdate <= prev(actdate) interval '2' second)
)
group by customer_id, match_num
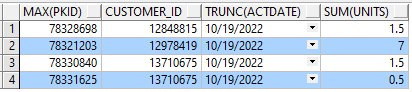
| PKID | CUSTOMER_ID | ACCDATE | UNITS |
|---|---|---|---|
| 78328698 | 12848815 | 10/19/2022 | 1.5 |
| 78321203 | 12978419 | 10/19/2022 | 7 |
| 78330840 | 13710675 | 10/19/2022 | 1.5 |
| 78331625 | 13710675 | 10/19/2022 | .5 |
The data is partitioned by customer_id, and for each ID the rows are ordered by actdate. The pattern and definition together define what constitutes a matching set - within a time window in this case - and each of those sets is assigned a match number. The data can then be grouped by the customer ID and that match number, and aggregates can then be calculated.
You can change the interval to make the matching window larger or smaller if necessary. It would work ordering and defining using datetime instead of actdate - not sure why you have both or if one is more appropriate than the other.