This might seem very basic but I am new to Pandas, the title might not be accurate but I have good screenshots below This is sort of a voting app
I have the vote_results dataframe:
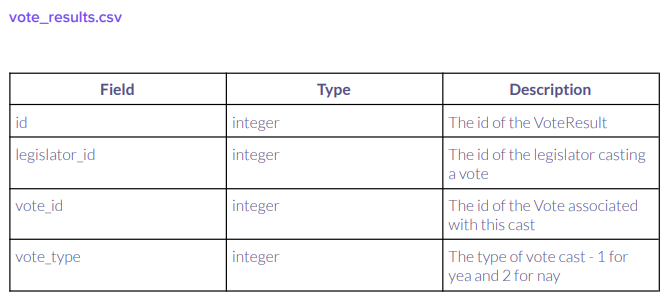
And the legislators dataframe:
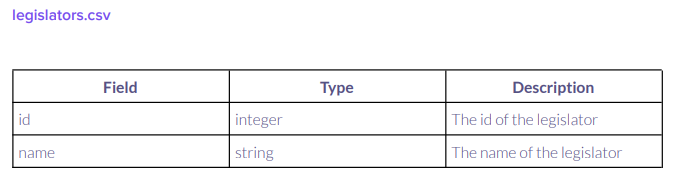
This is the dataframe that I want to accomplish:
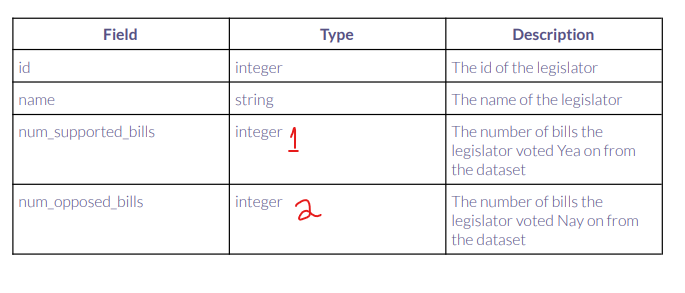
supported bills means a vote for yes opposed bills means a vote for no So I want to know how many times each legislator voted for yes (1) and no(2) I also need a join on the legislator's dataframe in order to include the legislator name
Really need some insight on this to understand better what can I do with dataframes in terms of manipulation.
I tried making some joins and group_by's but honestly I am not handling it very well, I can't print my group_by's and also don't know how to create an alias for count positive and negative votes grouped by legislator_id
CodePudding user response:
The logic is:
- Join the two dataframes by legislator id
- Group by legislator id
- Aggregate for supported bills and opposed bills count
- Legislator name is the first (or any) one in the group
vote_results = pd.DataFrame(data=[[1,"L1","V1",1],[2,"L1","V2",1],[3,"L2","V3",0],[4,"L2","V4",0],[5,"L3","V5",1],[6,"L3","V6",0]], columns=["id","legislator_id","vote_id","vote_type"])
legislators = pd.DataFrame(data=[["L1","ABC"],["L2","PQR"],["L3","XYZ"]], columns=["id","name"])
result_df = legislators.merge(vote_results[["legislator_id","vote_id","vote_type"]], left_on="id", right_on="legislator_id", how="left") \
.groupby("id") \
.apply(lambda x: pd.Series({
"name": str(x["name"].iloc[0]),
"num_supported_bills": len([v for v in x.vote_type if v==1]),
"num_opposed_bills": len([v for v in x.vote_type if v==0]),
})) \
.reset_index()
Output:
id name num_supported_bills num_opposed_bills
0 L1 ABC 2 0
1 L2 PQR 0 2
2 L3 XYZ 1 1