I have a file which has data separated with different spaces and column names are also having spaces.
Type Dec LookupTable Field Name Field Len Start Pos
NUM 0 _ sample data 5 1
NUM 0 _ sample data 10 6
CHAR 0 _ sample data 60 16
NUM 0 _ sample data 3 76
CHAR 0 _ sample data 60 79
CHAR 0 _ sample data 60 139
CHAR 0 _ sample data 60 199
CHAR 0 _ sample data 60 259
NUM 0 _ sample data 3 319
CHAR 0 _ sample data 60 322
CHAR 0 _ sample data 60 382
NUM 0 _ sample data 3 442
CHAR 0 _ sample data 60 445
I am reading this file like this
df= pd.read_fwf('./temp.txt', colspecs= 'infer')
and getting the dataframe with columns which are separated by spaces nan values
I want to drop the Nan columns and replace its previous columns name with the empty one.
How can we achieve this in an efficient way?
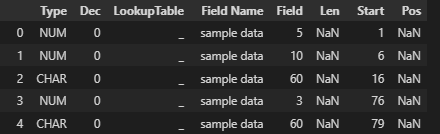
Expected outpuL:
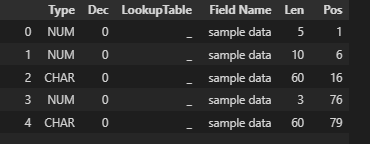
CodePudding user response:
I read the data from clipboard, so my DataFrame looks a little bit different than yours, that also means, you have to adjust the code, which shouldn't be a big deal
df.drop(columns=['Start', 'Pos']).rename(columns={'Name': 'Superman', 'Type':
'Mytype'}) # Very clear code, I think it doesn't need any explanation
df.dropna(axis=1,how='all').rename(columns={'Name': 'Superman', 'Type': 'Mytype'}) # the second way df.dropna(axis=1,how='all') means that it drops all columns with nans, but only if all of the values are nans.
Type Dec LookupTable Field Name Field.1 Len Start Pos
0 NUM 0 _ sample data 5 1 NaN NaN
1 NUM 0 _ sample data 10 6 NaN NaN
2 CHAR 0 _ sample data 60 16 NaN NaN
3 NUM 0 _ sample data 3 76 NaN NaN
4 CHAR 0 _ sample data 60 79 NaN NaN
5 CHAR 0 _ sample data 60 139 NaN NaN
6 CHAR 0 _ sample data 60 199 NaN NaN
7 CHAR 0 _ sample data 60 259 NaN NaN
8 NUM 0 _ sample data 3 319 NaN NaN
9 CHAR 0 _ sample data 60 322 NaN NaN
10 CHAR 0 _ sample data 60 382 NaN NaN
11 NUM 0 _ sample data 3 442 NaN NaN
12 CHAR 0 _ sample data 60 445 NaN NaN
df.drop(columns=['Start', 'Pos']).rename(columns={'Name': 'Superman', 'Type': 'Mytype'})
#df.dropna(axis=1,how='all').rename(columns={'Name': 'Superman', 'Type': 'Mytype'})
Out[30]:
Mytype Dec LookupTable Field Superman Field.1 Len
0 NUM 0 _ sample data 5 1
1 NUM 0 _ sample data 10 6
2 CHAR 0 _ sample data 60 16
3 NUM 0 _ sample data 3 76
4 CHAR 0 _ sample data 60 79
5 CHAR 0 _ sample data 60 139
6 CHAR 0 _ sample data 60 199
7 CHAR 0 _ sample data 60 259
8 NUM 0 _ sample data 3 319
9 CHAR 0 _ sample data 60 322
10 CHAR 0 _ sample data 60 382
11 NUM 0 _ sample data 3 442
12 CHAR 0 _ sample data 60 445
CodePudding user response:
import pandas as pd
import numpy as np
aaa = [(df.columns[i - 1], df.columns[i]) for i in range(1, len(df.columns)) if df[df.columns[i]].isna().all()]
bbb = dict(aaa)
df = df.drop(columns=np.array(aaa)[:, 1])
df.rename(columns=bbb, inplace=True)
print(df)
Here, in list comprehension aaa, paired tuples are created (on the left is the name of the column to be renamed, on the right is the name of the column to be deleted). Columns that are all with empty values are checked by the condition:
if df[df.columns[i]].isna().all()
A dictionary is created from aaa. drop removes the selected columns np.array(aaa)[:, 1] (to select an array by slice I wrap it with np.array).