EDITION.
How can I download addresses to the file from the terminal?
Can it be done with the help of WGET?
Can it be done with the help of CURL?
CodePudding user response:
To save the output of the wget command that you provided above, add the following at the end of your command line:
-O ${vidfileUniqueName}.${fileTypeSuffix}
Before that wget, you will need to define something like the following:
vidfileUniqueName=$(echo "${URL}" | cut -f10 -d\/ )
fileTypeSuffix="mp4|avi|mkv"
You need to choose only one of the suffix types from that list and remove the others.
CodePudding user response:
A couple of scripts, one reusable for other stuff.
Script #1: "normalize" lines so that they are not too long (Reformatter_01.sh):
#!/bin/sh
BASE=`basename "$0" ".sh" `
TMP="/tmp/tmp.$$.${BASE}"
{
if [ -n "${1}" ]
then
cat ${1}
else
cat
fi
} |
sed 's ^\t ' |
awk 'BEGIN{
splitter=";" ;
}{
rem=$0 ;
if( rem != "" || rem !~ /\s*/ ){
n=index( rem, "{" )
while( n != 0 ){
beg=substr( rem, 1, n ) ;
print beg ;
rem=substr( rem, n 1 ) ;
n=index( rem, "{" ) ;
} ;
if( rem != "" || rem !~ /\s*/ ){
print rem ;
} ;
} ;
}'
Script #2: Download and filter the page for URLs:
#!/bin/sh
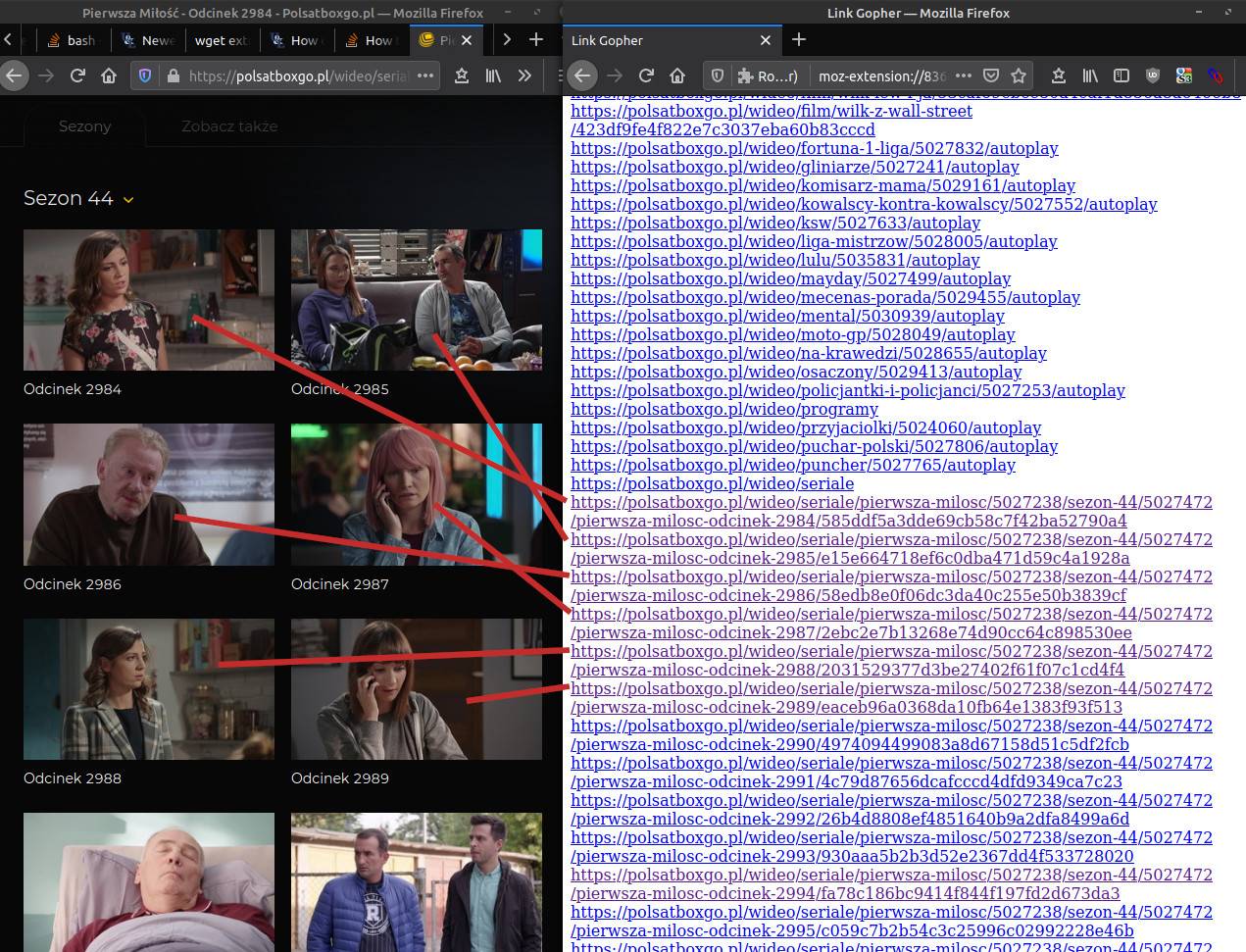
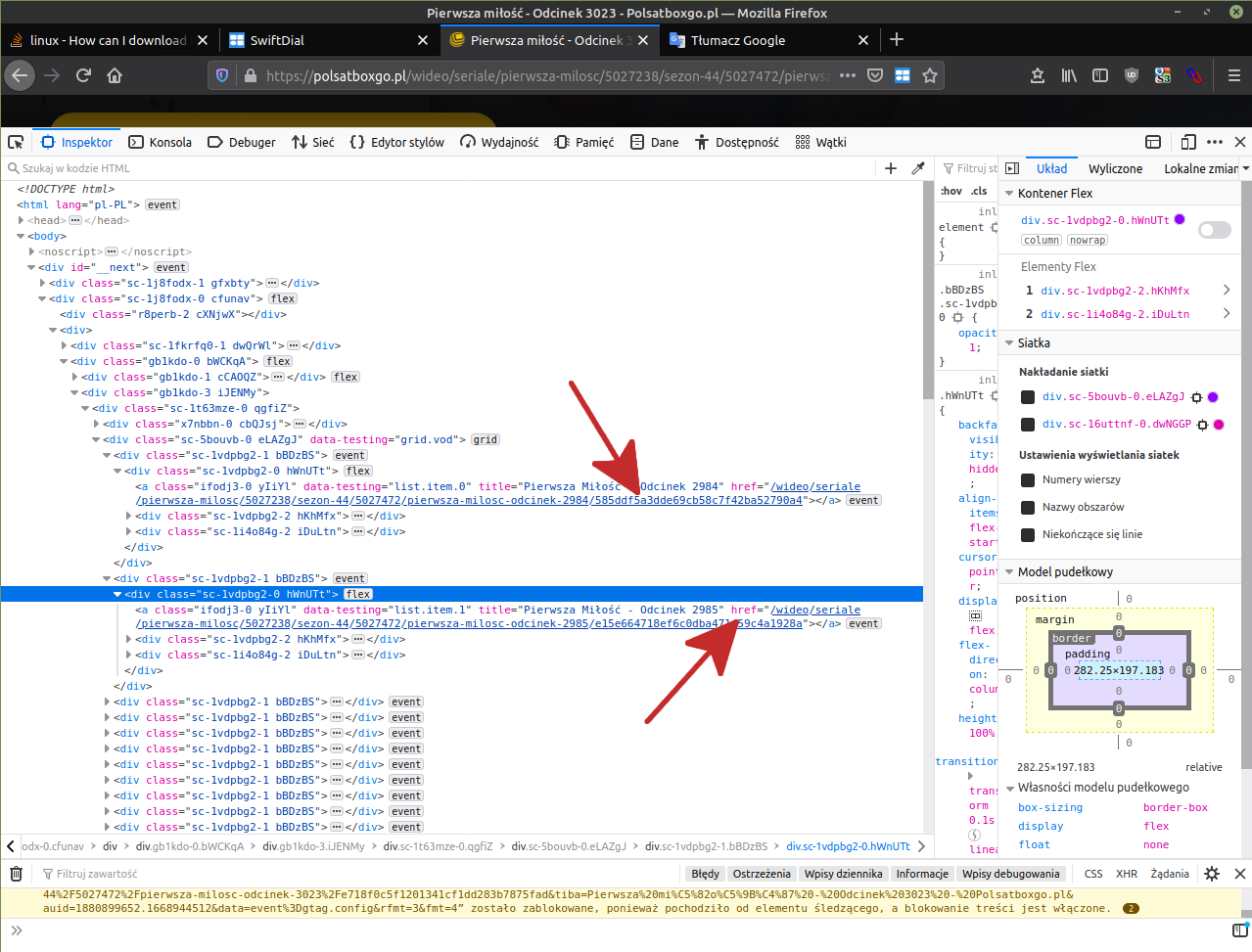
URL="https://polsatboxgo.pl/wideo/seriale/pierwsza-milosc/5027238/sezon-44/5027472/pierwsza-milosc-odcinek-2984/585ddf5a3dde69cb58c7f42ba52790a4"
BASE=$(basename "$0" ".sh")
TMP="${BASE}.tmp"
HARVESTED="${BASE}.harvest"
DISTILLED="${BASE}.urls"
if [ ! -s "${TMP}" ]
then
curl "${URL}" >"${TMP}"
fi
if [ ! -s "${TMP}.2" ]
then
Reformatter_01.sh "${TMP}" >"${TMP}.2" &
PID1=$!
tail -f "${TMP}.2" &
PID2=$!
wait ${PID1}
kill -9 ${PID2}
echo "\n\n END of REFORMATTING ...\n\n"
fi
### Separate any URLs from the rest of the HTML/CSS/JavaScript
grep 'http://' "${TMP}.2" | sed 's http\: \nhttp\: g' | sed 's https\: \nhttps\: g' >"${TMP}.3"
grep 'https://' "${TMP}.2" | sed 's https\: \nhttps\: g' | sed 's http\: \nhttp\: g' >>"${TMP}.3"
### Ignore any image URLs clearly not related to videos
grep '^http' "${TMP}.3" |
cut -f1-2 -d\: |
grep -v '\.png\"' |
grep -v '\.svg\"' |
grep -v '\.json\"' |
grep -v '\.jpg\"' |
grep -v '\.jpeg\"' |
sort |
uniq > "${HARVESTED}"
echo "\n Harvested Links (view of remaining URLs):"
more "${HARVESTED}"
### Distill for only grouping you are interesed. This could be a command line parameter. (NOTE: not same as full page URL)
grep 'https://polsatboxgo.pl/wideo/seriale/pierwsza-milosc/5027238/sezon-44/5027472/pierwsza-milosc-odcinek-' "${HARVESTED}" >"${DISTILLED}"
echo "\n Video Links:"
more "${DISTILLED}"
### add more coding for cleanup parsing here