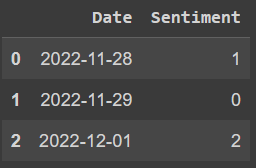
I have a dataframe with xenophobic and non-xenophobic tweets.
For each day, I want to count the number of tweets that have a sentiment of 1.
This is the Dataframes df_unevaluated
sentiment id date text
0 0 9.820000e 17 2018-04-05 11:43:31 00:00 but if she had stated another fact like that I may have thought...
1 0 1.170000e 18 2019-09-03 22:53:30 00:00 the worst thing that dude has done this week is ramble about the...
2 0 1.140000e 18 2019-06-28 17:43:07 00:00 i think immigrants of all walks of life should be allowed into...
3 0 2.810000e 17 2012-12-18 00:43:57 00:00 why is america not treating the immigrants like normal people...
4 1 8.310000e 17 2017-02-14 01:42:26 00:00 who the hell wants to live in canada anyhow the people there...
...
This is what I've tried:
# Put all tweets with sentiment = 1 into a Dataframes
for i in range(len(df_unevaluated)):
if df_unevaluated['sentiment'][i] == 1:
df_xenophobic = df_xenophobic.append(df_unevaluated.iloc[[i]])
# Store a copy of df_xenophobic in df_counts
df_counts = df_xenophobic
# Change df_counts to get counts for each date
df_counts = (pd.to_datetime(df_counts['date'])
.dt.floor('d')
.value_counts()
.rename_axis('date')
.reset_index(name='count'))
# Sort data and drop index column
df_counts = df_counts.sort_values('date')
df_counts = df_counts.reset_index(drop=True)
# Look at data
df_counts.head()
This was the output:
date count
0 2012-03-14 00:00:00 00:00 1
1 2012-03-19 00:00:00 00:00 1
2 2012-04-07 00:00:00 00:00 1
3 2012-04-10 00:00:00 00:00 1
4 2012-04-19 00:00:00 00:00 1
...
This is what I expected:
date count
0 2012-03-14 00:00:00 00:00 1
1 2012-03-15 00:00:00 00:00 0
2 2012-03-16 00:00:00 00:00 0
3 2012-03-17 00:00:00 00:00 0
4 2012-03-18 00:00:00 00:00 0
5 2012-03-19 00:00:00 00:00 1
6 2012-03-20 00:00:00 00:00 0
7 2012-03-21 00:00:00 00:00 0
...
These are some links I've read through: