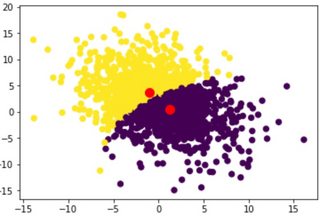
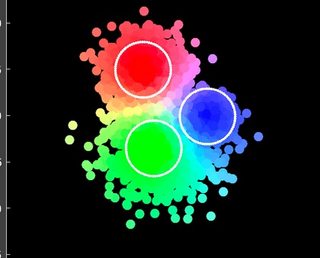
I have a normally distributed 2D dataset, and I am using the fcmeans library to perform fuzzy c-means clustering. I am able to plot the clusters with the red point indicating the cluster center (first image). However, I need to show a gradient similar to the second image where the fuzziness occurs. I am not sure how to implement this in Python and I haven't been able to find anything like it online.
from fcmeans import FCM
data = pd.read_csv("my_data.csv")
model = FCM(n_clusters=2)
model.fit(data)
centers = my_model.centers
hard_prediction_labels = my_model.predict(data)
soft_prediction_labels = my_model.soft_predict(data)
plt.scatter(data[:, 0], data[:, 1], c=hard_prediction_labels, s=30);
plt.scatter(data[:, 0].mean(), data[:, 1].mean(), s=60, c='red', label = 'Cntrds');
First Image:
Second Image (Color gradient example of what I want):
I believe that my mistake is coming from the fact that my labels are 1 or 0; however, I'm not sure how to define it in a way that would allow me to determine which points are borderline. I am able to obtain the probabilities from the soft prediction (as to the probability of the data point belonging to each cluster) using the soft_predict() function, but I am unsure of how to create a color gradient with it.
CodePudding user response:
Let's say that you have computed the (n_points, n_clusters) array prob, that for n_clusters being 2, looks like
print(prob)
# 0.61 0.39
# 0.55 0.45
# .... ....
# 0.07 0.93
Then you can do the following, to have a point that is more opaque when you have a higher probability of belonging to its cluster, and more transparent when it has a lower probabilty. I think this is what you want...
n_clusters = 2
...
for cluster in range(n_clusters):
plt.scatter(data[hard_prediction_labels==cluster, 0],
data[hard_prediction_labels==cluster, 1],
s=30,
alpha=0.8*prob[hard_prediction_labels==cluster, cluster])
plt.scatter(data[hard_prediction_labels==cluster, 0],
data[hard_prediction_labels==cluster, 1],
s=5,
alpha=1.0)
NB I haven't fcmeans so my code is untested, and is essentially based on informed speculation. You may need to adjust something to make it work.
EDIT
plotting twice each data cluster, with different sizes and transparencies, possibly give you a better visualization of your data.