I currently have this code that is able to retrieve the headlines of articles from und.com but I am also trying to get the a tag to the website page and the picture as well. I am struggling to get the code to display the correct data to the server and was wondering what I can do to get it to display the correct information. Below is the code I am trying right now.
const express = require("express");
const cheerio = require("cheerio");
const axios = require("axios");
const app = express();
app.post("/post", (req, res) => {
console.log("Connected to react");
res.redirect("/");
})
app.use(function(req, res, next) {
res.header('Access-Control-Allow-Origin', 'http://localhost:3000');
res.header('Access-Control-Allow-Methods', 'GET');
res.header('Access-Control-Allow-Headers', 'Content-Type');
next();
});
const PORT = process.env.PORT || 3002;
const website = "https://und.com";
let options = {
headers: {
"user-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
};
app.get("/", (req, res) => {
// Make the HTTP request using axios
axios(website, options)
.then(({data}) => {
const $ = cheerio.load(data);
console.log($)
const result = $(".post__meta h3 a:last-child")
.map((_, e) => $(e).text().trim())
.get();
console.log(result);
// Use cheerio to manipulate the HTML data
// Set the content type of the response to "text/html"
res.set("Content-Type", "text/html");
// Send the HTML data as the response
res.send(result);
})
.catch((error) => {
// The HTTP request failed
console.log("An error occurred:", error);
// Set the status code of the response to indicate an error
res.status(500);
// Send an error message as the response
res.send("An error occurred while making the HTTP request.");
});
})
app.listen(PORT, () => {
console.log(`server is running on PORT: ${PORT} `);
})
CodePudding user response:
Cheerio is fast method to web scraping. it's limitations is that it cannot handle dynamic sites.
A loading a browser would take a lot of resources because it has to load a lot of other things like the toolbar and buttons. These UI elements are not needed when everything is being controlled with code. Fortunately, there are better solutions – headless browsers.
A headless browser is simply a browser but without a graphical user interface. Think of it as a hidden browser.
Puppeteer is one of best control headless browser.
I made a program with express and puppeteer for your https://und.com web site .
It shows article list with title, image link, tag, link and category
Example
{
"title": "Together Irish",
"image_link": "https://und.com/imgproxy/BPEVHq4HccPML1rEeouDDHSwrg2Kd_uUryxDl6o1b-Q/fit/1024/619/ce/0/aHR0cHM6Ly91bmQuY29tL3dwLWNvbnRlbnQvdXBsb2Fkcy8yMDIyLzA5L3dlYi1oZWFkZXJfdG9nZXRoZXJpcmlzaC5wbmc.png",
"tag": "Together Irish",
"link": "https://und.com/stand-together-notre-dame-athletics-commitment-to-change/",
"category": "Athletics Communications"
},
puppeteer xpath selector idea for scrapping
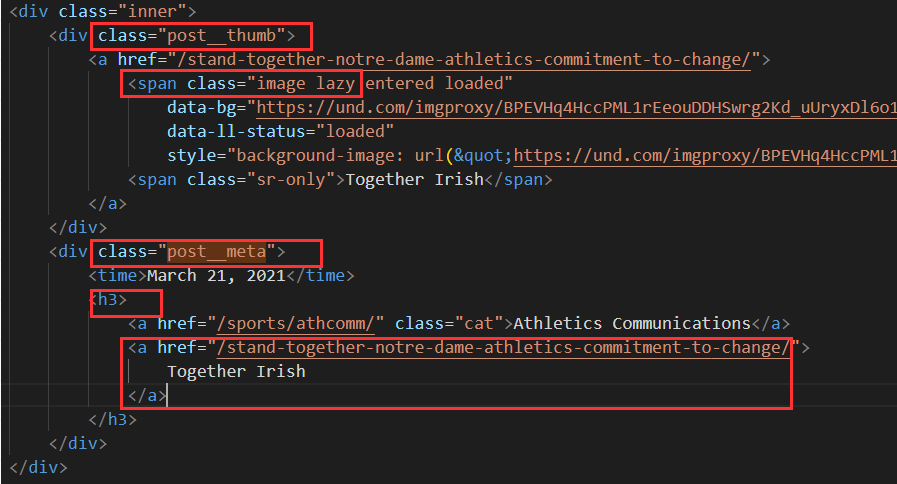
Title and image path
"div.post__thumb a span.image.lazy"
Title and category path
".post__meta h3 a:last-child"
Full code
const express = require("express")
const cors = require('cors');
const puppeteer = require("puppeteer");
const app = express()
const port = 3002
app.use(cors());
async function getArticles (url) {
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
articles = await page.evaluate(() => {
title_elements = document.querySelectorAll(".post__meta h3 a:last-child");
title_array = Array.from(title_elements);
image_elements = document.querySelectorAll("div.post__thumb a span.image.lazy");
image_array = Array.from(image_elements);
return title_array.map((title, i) => {
return {
title: image_array[i].nextElementSibling.textContent.trim(),
image_link: image_array[i].getAttribute('data-bg'),
tag: title.textContent.trim(),
link: 'https://und.com' title.getAttribute('href'),
category: title.previousElementSibling.textContent.trim()
}
});
});
await browser.close();
return Promise.resolve(articles);
} catch (error) {
return Promise.reject(error);
}
}
app.get("/info", (req, res) => {
getArticles('https://und.com/')
.then((articles) => {
console.log(articles);
console.log(articles.length);
res.status(200).json(articles)
})
})
app.listen(port, ( ) => console.log(`Server started, port: ${port}`))
Install and run it
npm install express cors puppeteer
node server.js
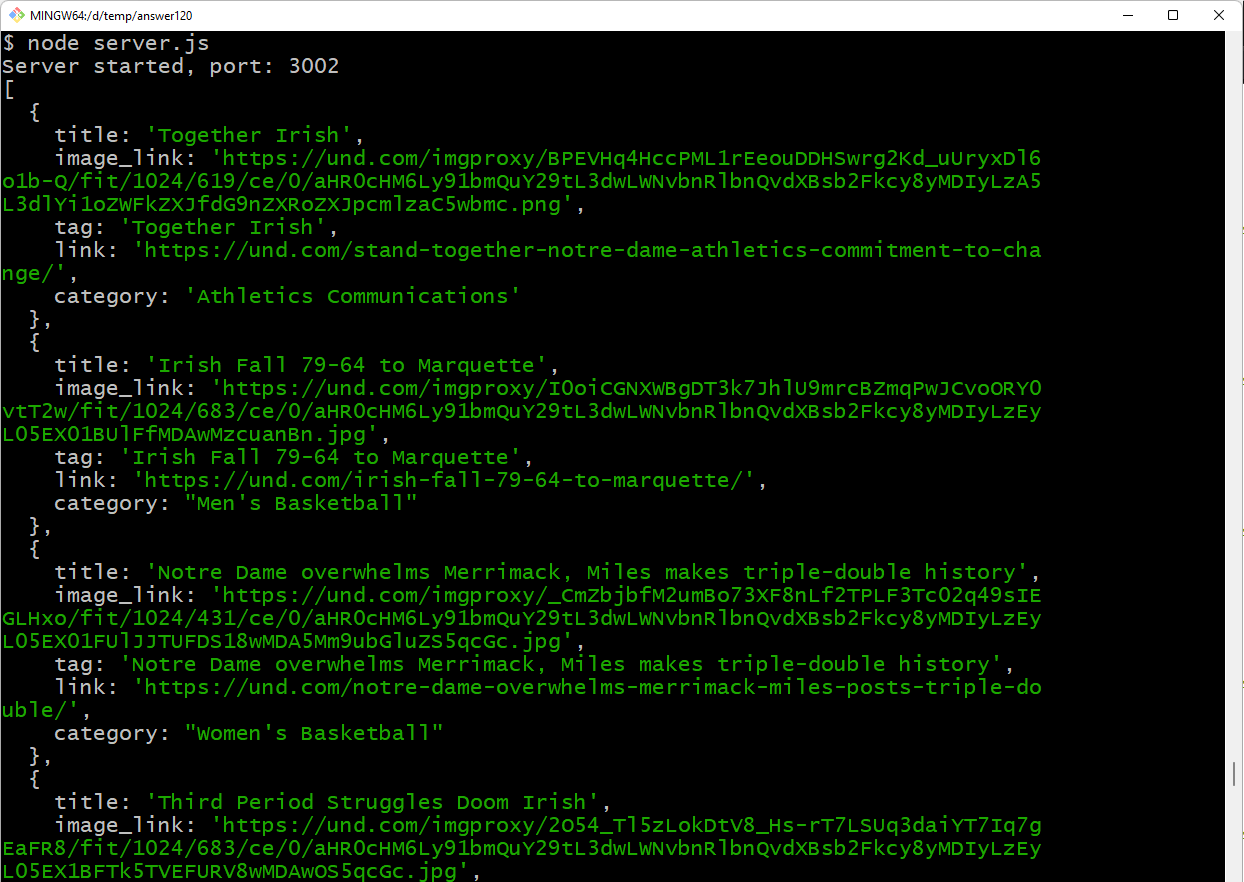
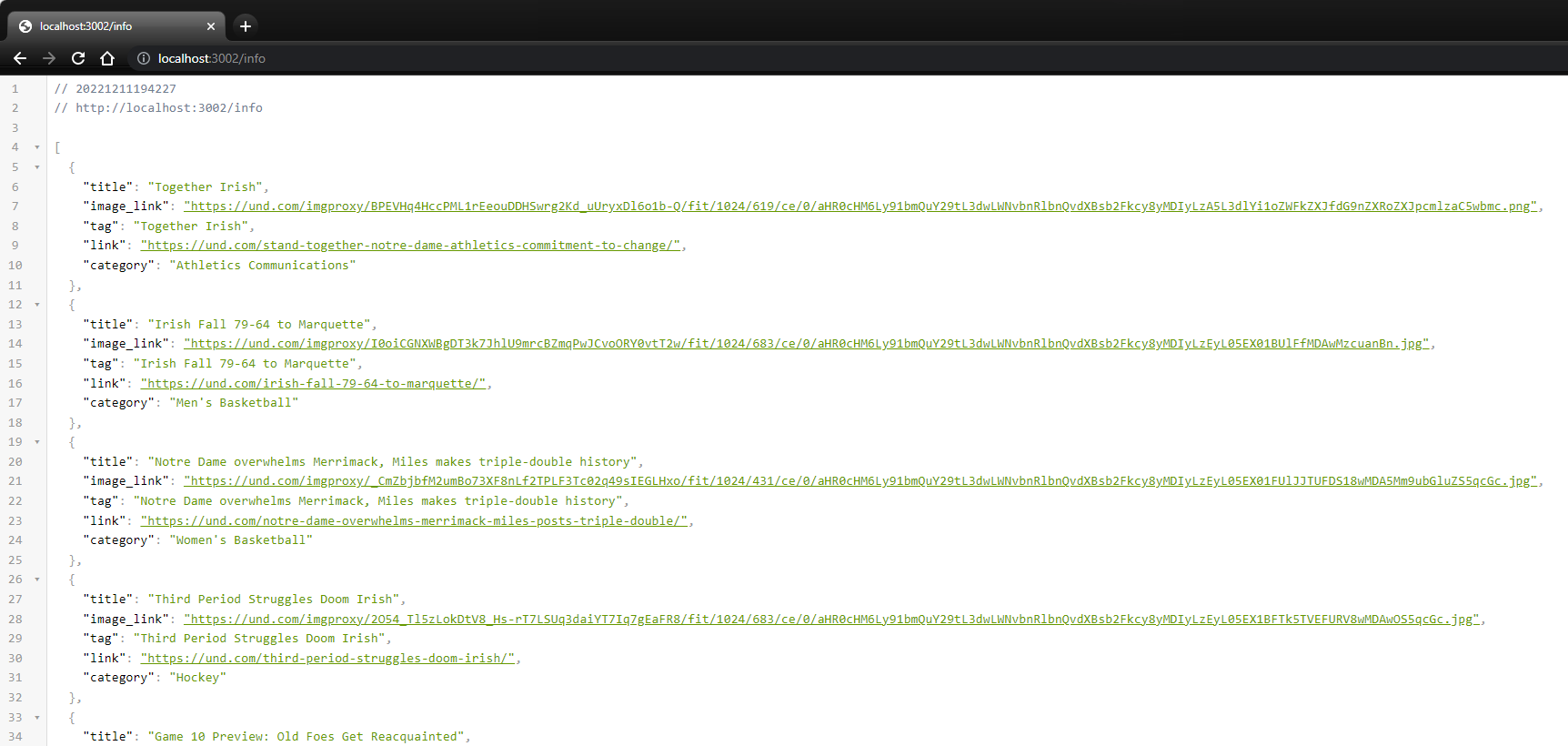
Result - if access express server
http://localhost:3002/info
CodePudding user response:
Here is a pure cheerio solution:
// define function which accepts body and cheerio as args
function extract(input, cheerio) {
// return object with extracted values
let $ = cheerio.load(input);
let posts = $(".post__meta").map(function () {
let h3 = $('h3', this);
let item = {
category: h3.find('a:nth-child(1)').text().trim(),
title: h3.find('a:nth-child(2)').text().trim(),
img: $(this).prev().find('.image').attr('data-bg')
};
return item;
}).toArray();
return posts;
}
results:
[
{
"category": "Athletics Communications",
"title": "Together Irish",
"img": "https://und.com/imgproxy/BPEVHq4HccPML1rEeouDDHSwrg2Kd_uUryxDl6o1b-Q/fit/1024/619/ce/0/aHR0cHM6Ly91bmQuY29tL3dwLWNvbnRlbnQvdXBsb2Fkcy8yMDIyLzA5L3dlYi1oZWFkZXJfdG9nZXRoZXJpcmlzaC5wbmc.png"
},
{
"category": "Football",
"title": "Mayer, Alt and Foskey Named Associated Press All-Americans",
"img": "https://und.com/imgproxy/hGlq4hjeum4XvBCd69FPHAKHMz1sbhondxvzePmvYdk/fit/1024/576/ce/0/aHR0cHM6Ly91bmQuY29tL3dwLWNvbnRlbnQvdXBsb2Fkcy8yMDIyLzEyL2Fzc29jaWF0ZWQtcHJlc3MtMTZ4OS0xLmpwZw.jpg"
}
]
run this cheerio extractor on test HTML here: https://scrapeninja.net/cheerio-sandbox?slug=eaa3eeb5c55284274880b4c2714715a1ffe6839c