I have to copy a file from an HTTP source to Azure Blob Storage (ABS) using a copy activity in Azure Data Factory (ADF).
The fully-qualified path to the file has a date-stamp in it, so it keeps changing (e.g., http://www.example.com/files/2022-12-13.zip). Further I want to expand it into a directory in ABS that is also named based on the date (e.g., <blob>/2022-12-13/).
Is there a way to do this in ADF (preferably one that doesn't involve writing code)?
CodePudding user response:
Since, your source is HTTP, you can build the URL dynamically like http://www.example.com/files/yyyy-MM-dd.zip where yyyy-MM-dd is today's date.
- Using
copy dataactivity, create a source dataset forHTTPsource with configurations set as below. Give the base URL ashttp://www.example.com/files/and relative URL as shown below:
@{formatDateTime(utcNow(),'yyyy-MM-dd')}.zip
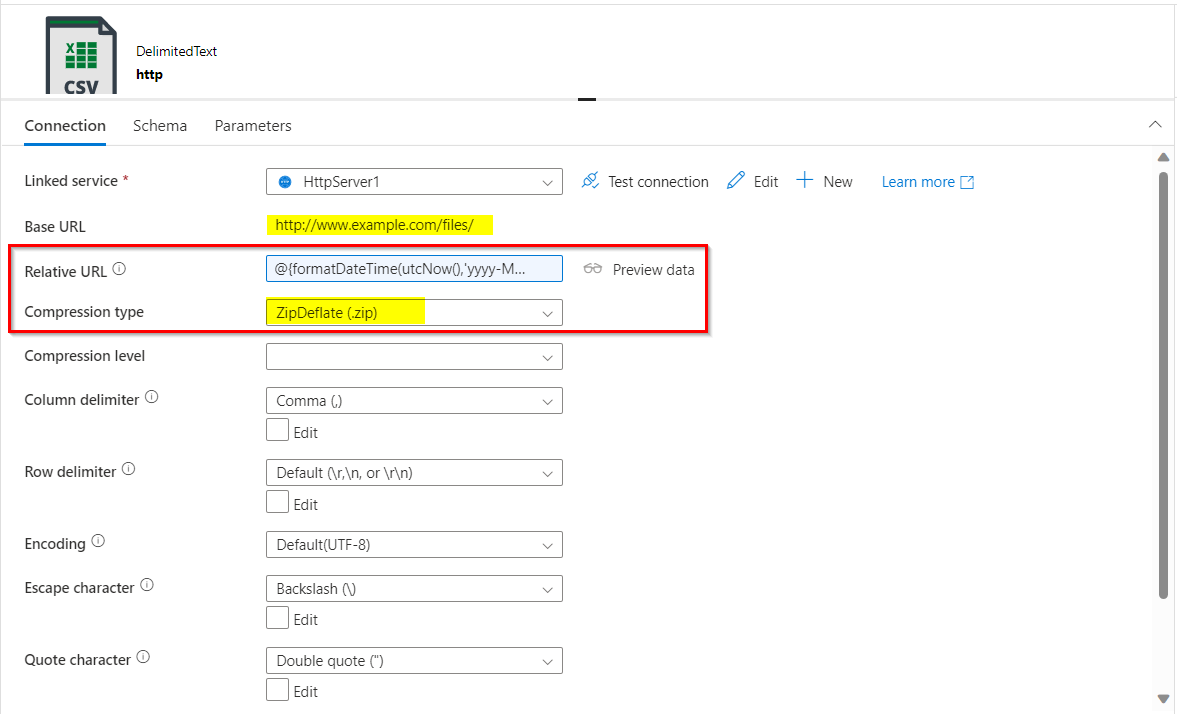
Don't select
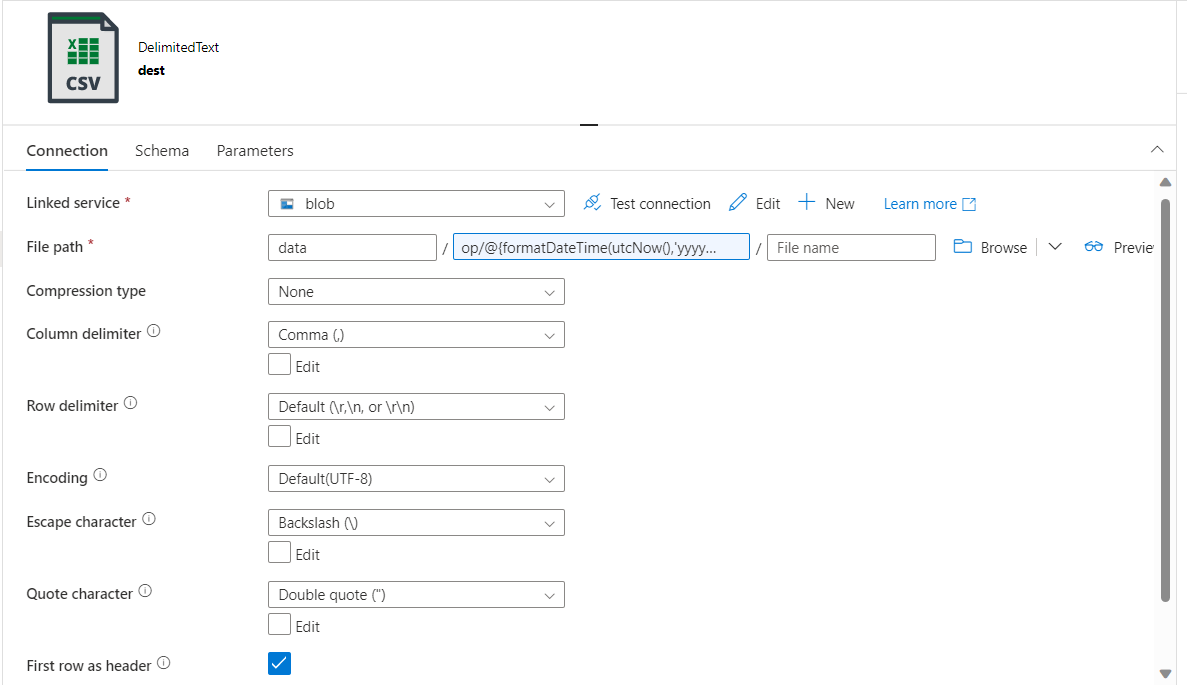
Preserve zip file name as folderoption.Now for sink, you can create your dataset for blob storage. Since you want to store it in a folder with
yyyy-MM-dd, configure your blob storage sink dataset as shown below:
#folder structure here would be "op/yyyy-MM-dd/"
#remove or add before the dynamic content to define your folder structure.
op/@{formatDateTime(utcNow(),'yyyy-MM-dd')}
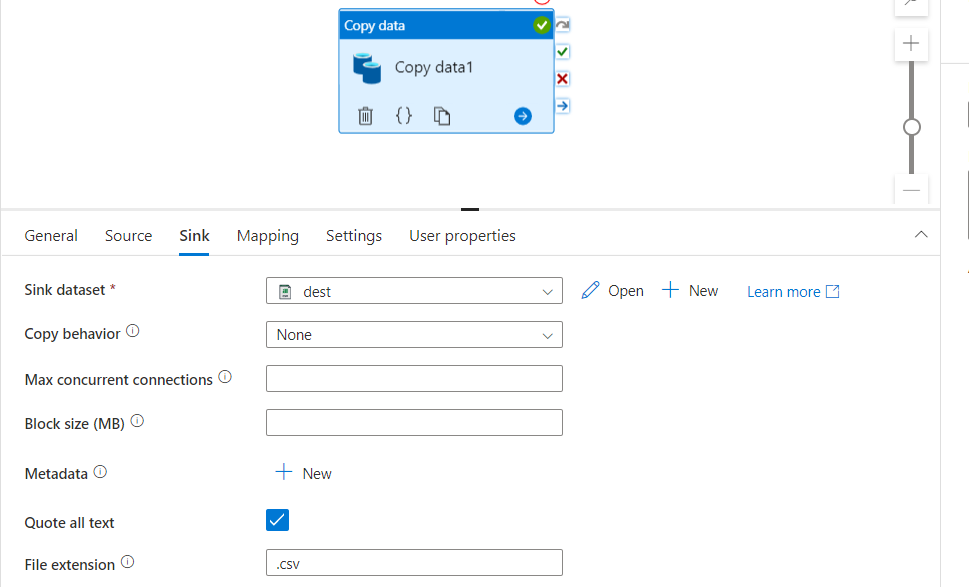
- Also change the file extension as required in sink settings:
CodePudding user response:
I had a similar requirement lately, and ended up solving this with code. You can either use an azure function to get the list of files from your data lake folder, or use a Synapse Notebook. Based on your requirements, you can select the latest/earliest/some other criterion in that specific blob --> folder. Here's how I did it:
# Use DataLakeServiceClient class from ADLS2 data lake API.
# Can probably use similar API for blob storage.
from azure.storage.filedatalake import DataLakeServiceClient
# Function that initializes a connection to the data lake
def initialize_storage_account_connection(storage_account_name, storage_account_key):
service_client = DataLakeServiceClient(account_url=f"https://{storage_account_name}.dfs.core.windows.net",
credential=storage_account_key)
return service_client
# Function that returns the file paths of files in a certain folder
def list_directory_contents():
# Initialize a file system client for blob container "raw"
file_system_client = service_client.get_file_system_client(file_system="raw")
# Get the path objects of respective parquet files in specific table folders under the "raw" blob container
paths = file_system_client.get_paths(path=path_to_folder)
# Parse paths into a proper list
path_list = [path.name for path in paths]
return path_list
# Function that determines the most recent change file (I Needed most recent file but perhaps adapt according to needs)
def get_most_recent_timestamp():
# Example of a path: 'change_data/test_table/changes_test_table2022-10-13T17:57:30.parquet'
# Determine prefix length of path that has to be stripped away (for example: "change_data/test_table/changes_test_table" has a length of 41)
prefix_length = len(path_to_change_table) len('changes_') len(table_name) 1
# Determine suffix length of path that has to be stripped away
suffix_length = len('.parquet')
# Strip away prefix and suffix for each path so only the timestamp remains. In example, only 2022-10-13T17:57:30 would remain.
# Do this for all paths in directory_path_list
time_stamp_list = [i[prefix_length:-suffix_length] for i in directory_path_list]
# Sort the time stamps
sorted_time_stamp_list = sorted(time_stamp_list, reverse=True)
# Get and return most recent timestamp
most_recent_timestamp = sorted_time_stamp_list[0]
return most_recent_timestamp
And then just call the function:
path_to_change_table = f'change_data/{table_name}'
#TODO: get key from key-vault or use a managed identity
service_client = initialize_storage_account_connection('your_sa', 'your_sa_key')
directory_path_list = list_directory_contents()
most_recent_timestamp = get_most_recent_timestamp()
print(most_recent_timestamp)