I'm trying to train a forecasting model on several backtest dates and model parameters. I wrote a custom function that basically takes an average of ARIMA, ETS, and a few other univariate and multivariate forecasting models from a dataset that's about 10 years of quarterly data (40 data points). I want to run this model in parallel on thousands of different combinations.
The custom model I wrote looks like this
def train_test_func(model_params)
data = read_data_from_pickle()
data_train, data_test = train_test_split(data, backtestdate)
model1 = ARIMA.fit(data_train)
data_pred1 = model1.predict(len(data_test))
...
results = error_eval(data_pred1, ..., data_pred_i, data_test)
save_to_aws_s3(results)
logger.info("log steps here")
My multiprocessing script looks like this:
# Custom function I work that trains and tests
from my_custom_model import train_test_func
commands = []
if __name__ == '__main__':
for backtest_date in target_backtest_dates:
for param_a in target_drugs:
for param_b in param_b_options:
for param_c in param_c_options:
args = {
"backtest_date": backtest_date,
"param_a": param_a,
"param_b": param_b,
"param_c": param_c
}
commands.append(args)
count = multiprocessing.cpu_count()
with multiprocessing.get_context("spawn").Pool(processes=count) as pool:
pool.map(train_test_func, batched_args)
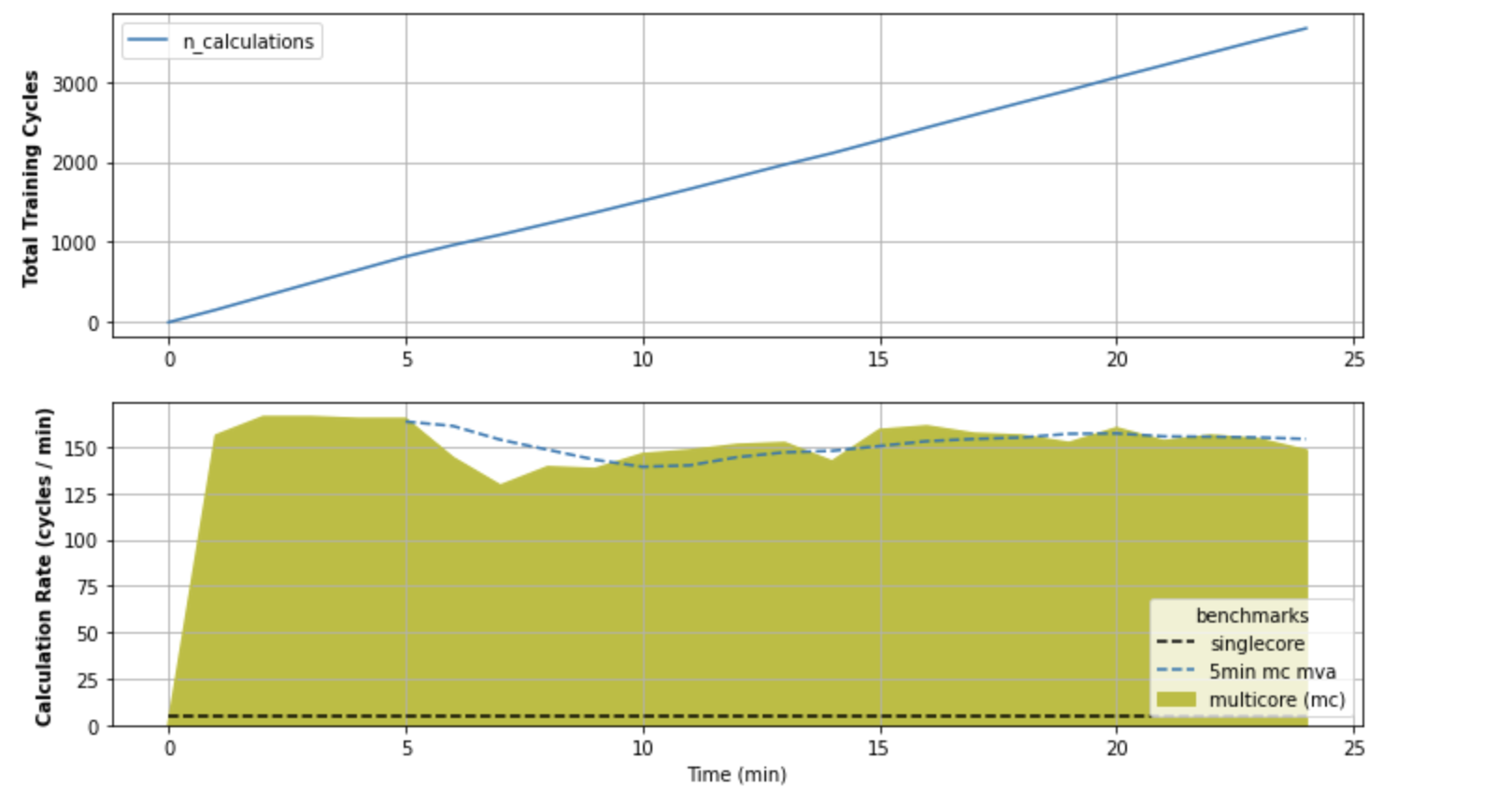
I can get relatively fast results for the first 200 or so iterations, roughly 50 iterations per min. Then, it drastically slows down to ~1 iteration per minute. For reference, running this on a single core gets me about 5 iterations per minute. Each process is independent and uses a relatively small dataset (40 data points). None of the processes need to depend on each other, either--they are completely standalone.
Can anyone help me understand where I'm going wrong with multiprocessing? Is there enough information here to identify the problem? At the moment, the multiprocessing versions are slower than single core versions.
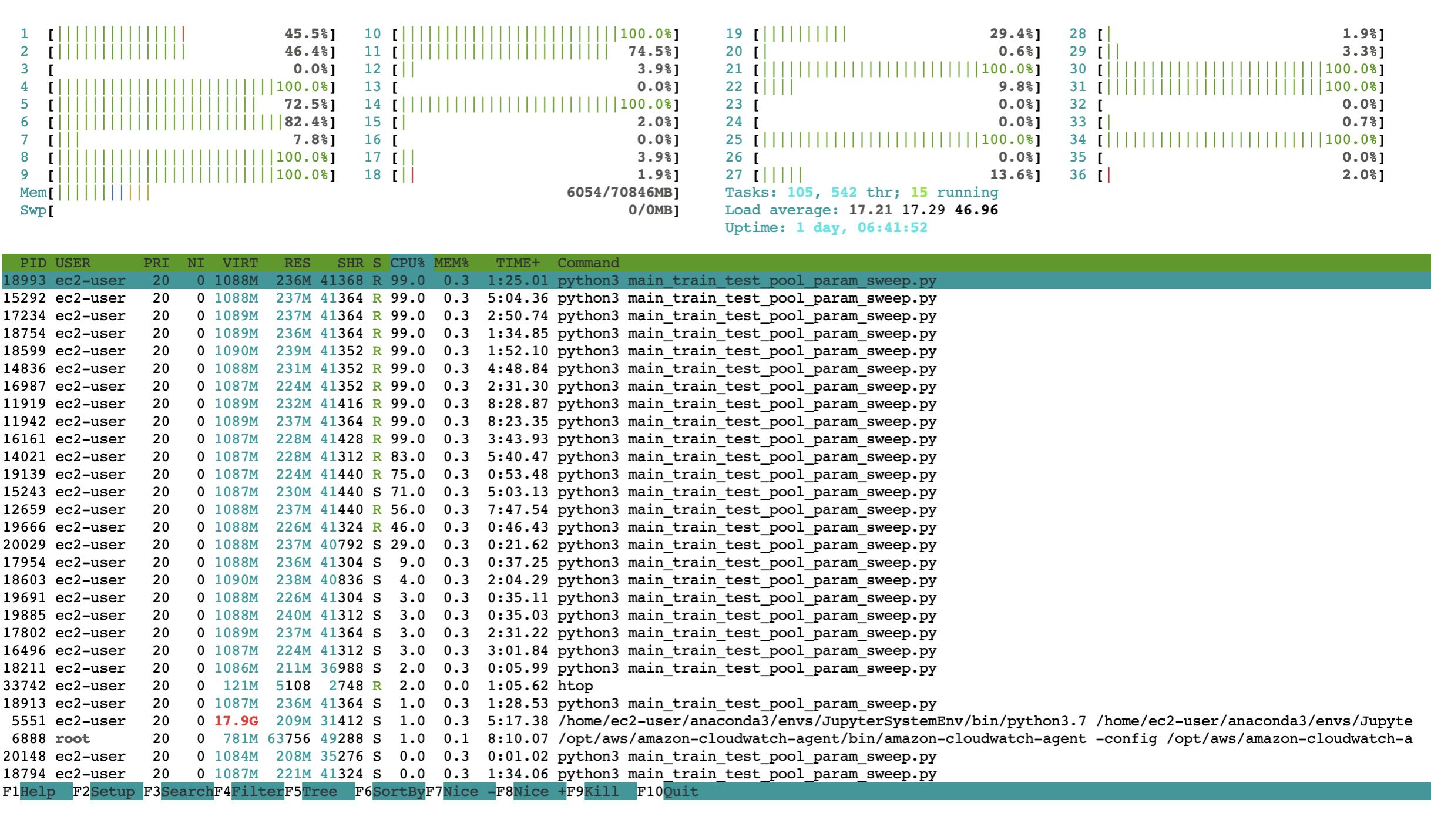
Attaching performance output


CodePudding user response:
I found the answer. Basically my model uses numpy, which, by default, is configured to use multicore. The clue was in my CPU usage from the top command.
This