I'm trying to check if a sentence only has Sinhala words (they can be nonsense words as long as they are written in Sinhala). Sometimes there can be English words in a sentence mixed with sinhala words. The thing is sometimes Sinhala words give True when checked with isalpha() giving incorrect results in my classification.
for example I did something like this.
for i in ['මට', 'කෑම', 'කන්න', 'ඕන']:
print(i.isalpha())
gives
True
False
False
True
Is there a way to overcome this
CodePudding user response:
How isalpha works is by checking if the category of a character for Unicode is Lm, Lt, Lu, Ll, or Lo. See below for their meaning.
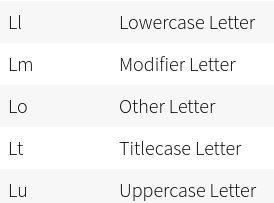
This "breaks" python when characters are joint together.
In your first example if we see ම or ට the category (from the lookup tool below) is Lo. This is valid so it gives us True
In your second example, the first letter is කෑ which is actually two characters (ක and ෑ). The category for ෑ is not at letter one so it returns False.
Long story short, Python is technically right. If you we were to do what you indented you would have to split joint characters and then remove the extra characters added on. So, it is complicated. There may be a library out there that does this but I do not know any.
Cheers
source: https://docs.python.org/3/library/stdtypes.html#str.isalnum character lookup: https://www.compart.com/en/unicode/
CodePudding user response:
this might help
from string import ascii_lowercase, ascii_uppercase
all = ascii_uppercase ascii_lowercase
for i in ['මට', 'කෑම', 'කන්න', 'ඕන']:
print(i in all)
here is the output
False
False
False
False