I am trying to implement my own function. Below you can see my code and data
import pandas as pd
import numpy as np
data = {'type_sale':[100,0,24,0,0,20,0,0,0,0],
'salary':[0,0,24,80,20,20,60,20,20,20],
}
df1 = pd.DataFrame(data, columns = ['type_sale',
'salary',])
def cal_fun(type_sale,salary):
if type_sale > 1:
new_sale = 0
elif (type_sale==0) and (salary >1):
new_sale = (np.random.choice, 10, p=[0.5,0.05]))/2 ###<-This line here
return (new_sale)
df1['new_sale']=cal_fun(type_sale,salary)
So with this function, I want to randomly select 50 percent of rows (with np.random) in the salary column. These randomly selected rows need to have zero at the same time in the column type_sale, and after that, I want to divide these values by 2.
I tried with the above function, but I am not sure that I made this thing properly. So can anybody help me with how to solve this problem?
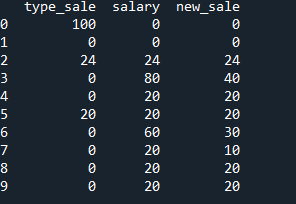
In the end, I expect to have the table as the table is shown below.
Your ideas, please implement in the above format of function
CodePudding user response:
To get a 50% choice you only need to choose 1 of 2 options. If I understand your issue then:
import pandas as pd
import random
data = {'type_sale':[100,0,24,0,0,20,0,0,0,0],
'salary':[0,0,24,80,20,20,60,20,20,20],
}
df1 = pd.DataFrame(data, columns = ['type_sale',
'salary',])
def cal_fun(row):
t = row['type_sale']
s = row['salary'
if (t==0) and (s > 0):
select = random.choice([0, 1])
if select:
return s/2
else:
return s
else:
return 0
df1['new_sale']=df1.apply(lambda x: cal_fun(x), axis = 1)
print(df1)
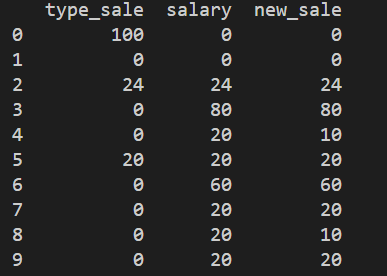
which gives:
type_sale salary new_sale
0 100 0 0.0
1 0 0 0.0
2 24 24 0.0
3 0 80 40.0
4 0 20 20.0
5 20 20 0.0
6 0 60 30.0
7 0 20 20.0
8 0 20 20.0
9 0 20 10.0
CodePudding user response:
import pandas as pd
import numpy as np
data = {'type_sale':[100,0,24,0,0,20,0,0,0,0],
'salary':[0,0,24,80,20,20,60,20,20,20],
}
df1 = pd.DataFrame(data, columns = ['type_sale',
'salary',])
def cal_fun(type_sale,salary):
# get random 50 % row from type_sale column
random_indexes = np.random.randint(0,len(df1),int(len(df1["type_sale"])/2))
random_rows = df1.iloc[random_indexes][type_sale == 0].index # get index which is type_sale == 0
new_sale = salary.copy()
new_sale[random_rows] /= 2
return new_sale
df1['new_sale']=cal_fun(df1["type_sale"],df1["salary"])
print(df1)
If I totaled half the number of rows, we chose random rows and we extracted the ones with type_sale == 0 from these rows and using these we extracted the salary by dividing it by 2 and created the new_salary column. I understood the problem in this way, I may have misunderstood the problem, if it is to get 5 random indexes with type_sale == 0 If you want, update the following lines of code:
random_indexes = np.random.choice(type_sale.index,5)
df1['new_sale']=cal_fun(df1[df1["type_sale"] == 0],df1["salary"])
You can also use apply function
def cal_fun(row):
if row["type_sale"] == 0:
row["new_salary"] /= 2
return row
df1["new_salary"] = df1["salary"].copy()
random_indexes = np.random.choice(df1[df1["type_sale"] == 0].index,5)
df1.iloc[random_indexes] = df1.iloc[random_indexes].apply(cal_fun,axis = 1)
print(df1)