I have a dataframe of calls received per month for my business and am trying to split them up into if they were called back, scheduled, or cancelled. I am trying to create functions that evaluate based on meeting conditions how many in each category there were for each month.
For example, I want to fill a new column Calls Scheduled based on if the call was marked as scheduled. The idea is to iterate through all the rows and append to a list if this condition is met, then the length of the list becomes the value in Calls Scheduled.
What I have:
def scheduled(df_to_iterate, df_to_output, month):
calls_scheduled = []
for row in df_to_iterate:
if df_to_iterate['Month'] == month:
if df_to_iterate['Scheduled'] != np.nan:
calls_scheduled.append(1)
df_to_output.loc[month, 'Calls Scheduled'] = len(calls_scheduled)
scheduled(df2021, df, 'March')
I have two dataframes. df2021 contains all calls received and marked as called back, scheduled, or cancelled. df contains the total calls of each month by year and is what should be receiving the Calls Scheduled column.
Here is an example of data in df2021:
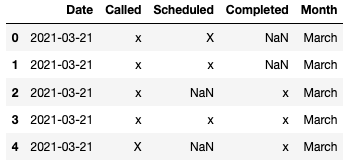
And here is the output df with the new Calls Scheduled column:
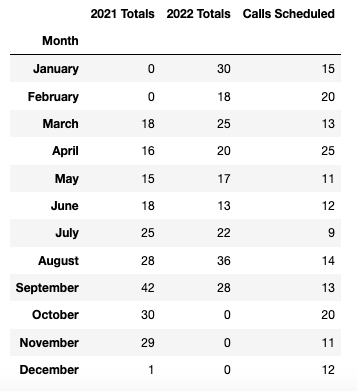
After running the function, I receive a ValueError. I assume it is something basic, but I can't figure it out:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[34], line 11
7 calls_scheduled.append(1)
9 df_to_output.loc[month, 'Calls Scheduled'] = len(calls_scheduled)
---> 11 scheduled(df2021, df, 'March')
Cell In[34], line 5, in scheduled(df_to_iterate, df_to_output, month)
2 calls_scheduled = []
4 for row in df_to_iterate:
----> 5 if df_to_iterate['Month'] == month:
6 if df_to_iterate['Scheduled'] != np.nan:
7 calls_scheduled.append(1)
File ~/opt/anaconda3/envs/Python3.10/lib/python3.10/site-packages/pandas/core/generic.py:1527, in NDFrame.__nonzero__(self)
1525 @final
1526 def __nonzero__(self) -> NoReturn:
-> 1527 raise ValueError(
1528 f"The truth value of a {type(self).__name__} is ambiguous. "
1529 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."
1530 )
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
CodePudding user response:
I think you don't need to use any loop. Can you try this:
def scheduled(df_to_iterate, df_to_output, month):
calls_scheduled = len(df_to_iterate[(df_to_iterate['Month']==month) & (df_to_iterate['Scheduled'].notnull())])
df_to_output.loc[month, 'Calls Scheduled'] = len(calls_scheduled)
Note: In your function, you are getting an error because df_to_iterate['Month'] returns a series not a string value.
CodePudding user response:
For count match values of masks use sum, Trues are processing like 1:
def scheduled(df_to_iterate, df_to_output, month):
count = ((df_to_iterate['Month']==month) & df_to_iterate['Scheduled'].notna()).sum()
df_to_output.loc[month, 'Calls Scheduled'] = count
return df_to_output
If need count each month aggregate sum and mapping by Index.map:
def scheduled(df_to_iterate, df_to_output):
s = df_to_iterate['Scheduled'].notna().groupby(df_to_iterate['Month']).sum()
df_to_output['Calls Scheduled'] = df_to_output.index.map(s)
return df_to_output
And for 3 new columns solution is:
def all_calls(df_to_iterate, df_to_output):
cols = ['Called','Scheduled','Completed']
df1 = df_to_iterate[cols].notna().groupby(df_to_iterate['Month']).sum()
df_to_output = df_to_output.join(df1.add_prefix('Calls '))
return df_to_output