I'm using Selenium and trying to scrape text within a < p > from an element with default attributes <aria-hidden='true' style='display:none;'> that changes upon collapsing the element by clicking 'View Details'.
I can still see the element via inspect but none of my x-pathing seems to work. I've included my code below:
import datetime
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
url = 'https://www.finder.com.au/savings-accounts/best-savings-accounts'
driver.get(url)
savings = WebDriverWait(driver, 30).until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="comparison-table-0000000000"]/tbody//tr')))
for i in range(1, len(savings) 1):
savings_details = WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, f'//*[@id="comparison-table-0000000000"]/tbody/tr[{i}]//p'))).text
print(savings_details)
X-Path of the first listing (without collapsing)
//*[@id="comparison-table-0000000000"]/tbody/tr[1]/td[10]/div/div/div/div/div/div/dl/dd/p[1]
I tried this exact x-path and it returns an error. Now I tried :
//*[@id="comparison-table-0000000000"]/tbody/tr[{i}]//p
No more error but it returns empty spaces.
Is the issue just my x-pathing? Or is there a different approach to scraping elements that are not immediately visible to the web driver?
CodePudding user response:
These elements containing no text until you click apprpriate 'View Details' button. This can be seen with dev tools:
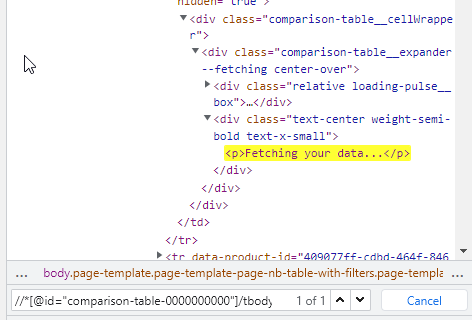
p element is empty, contains no text.
Again, the text there is dynamically generated by clicking 'View Details' button. This, of couse, makes more changes on the page, not only the p element text is added.
CodePudding user response:
Without clicking on the view details you will not be able to fetch the data since it is being dynamically generated as it has been said in another answer, but what you can do is iterate over it and open each one which is fairly easy, here the code for it,
time.sleep(20)
j=0
for i in range(12):
j =1
viewClass = '/html/body/div[1]/div/div[5]/div[2]/div[2]/div[4]/section/form/table/tbody/tr[' str(j) ']/td[8]/div/a[2]'
driver.execute_script("arguments[0].click();", WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, viewClass))))
savings = WebDriverWait(driver, 30).until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="comparison-table-0000000000"]/tbody//tr')))
for i in range(1, len(savings) 1):
savings_details = WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, f'//*[@id="comparison-table-0000000000"]/tbody/tr[{i}]//p'))).text
print(savings_details)
In this specific website, clicking view details throw an exception called ElementClickInterceptedException, which can be resolve by doing this ElementClickInterceptedException: Message: element click intercepted Element is not clickable error clicking a radio button using Selenium and Python