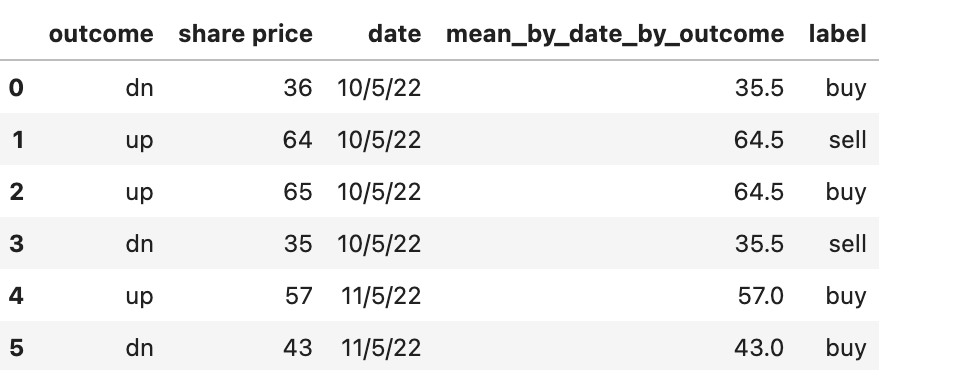
timestamp IFPID Outcome Share Price Trade Qty Date
0 10/05/2022 08:04 SP3K4K5 dn 36 100 2022-10-05
1 10/05/2022 08:04 SP3K4K5 up 64 100 2022-10-05
2 10/05/2022 08:04 SP3K4K5 up 65 100 2022-10-05
3 10/05/2022 08:04 SP3K4K5 dn 35 100 2022-10-05
4 11/05/2022 00:54 SP3K4K5 up 57 64 2022-11-05
5 11/05/2022 00:54 SP3K4K5 dn 43 64 2022-11-05
I want to new variable Expected(a binary class with buy or sell) which will be computed based on the aggregation of the the Date and Outcome variables by the share price variable and assign buy when the mean of the of up outcome for a particular date is higher than the mean of the dn outcome.
CodePudding user response:
To iterate through a variable in a DataFrame and aggregate by another variable, you can use a for loop and the groupby method. Here's an example of how you might do this:
import pandas as pd
# Assume we have a DataFrame with columns 'var1' and 'group'
df = pd.DataFrame({'var1': [1, 2, 3, 4, 5], 'group': ['A', 'A', 'B', 'B', 'B']})
# Create an empty list to store the aggregated values
agg_values = []
# Iterate through the unique values in 'var1'
for var in df['var1'].unique():
# Aggregate the data for each value of 'var1' by 'group' and store the result
agg = df[df['var1'] == var].groupby('group').mean()
agg_values.append(agg)
# Concatenate all of the aggregated DataFrames into a single DataFrame
agg_df = pd.concat(agg_values)
# Add a new column with labels based on the values of 'var1'
agg_df['label'] = [f'Value {v}' for v in df['var1'].unique()]
print(agg_df)
This will output a DataFrame with the aggregated values for each unique value of var1, and a new column label with labels based on the values of var1.
var1 label
group
A 1.5 Value 1
B 4.0 Value 2
B 5.0 Value 3
CodePudding user response:
import pandas as pd
import numpy as np
df = pd.DataFrame({'outcome': ['dn', 'up', 'up', 'dn', 'up', 'dn'], 'share price': [36,64,65,35,57,43],'date':['10/5/22', '10/5/22', '10/5/22', '10/5/22', '11/5/22','11/5/22']})
print(df)
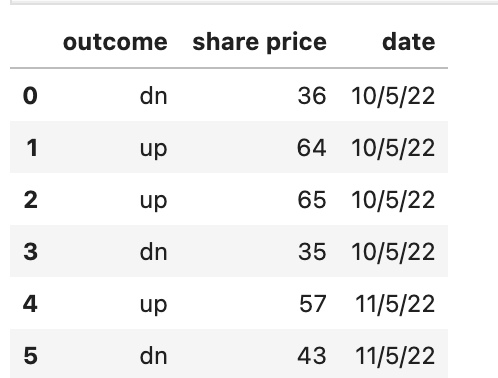
df['mean_by_date_by_outcome'] = df.groupby(['date','outcome'])['share price'].transform(np.mean)
df.loc[:,'label'] = 'buy'
df.loc[df['share price']<df['mean_by_date_by_outcome'],'label'] = 'sell'
df