Background and goal: I have two tables: counts and picks. The base table is counts and is what I want the result of all of this to be merged with. Screenshot of a reproducible example below.
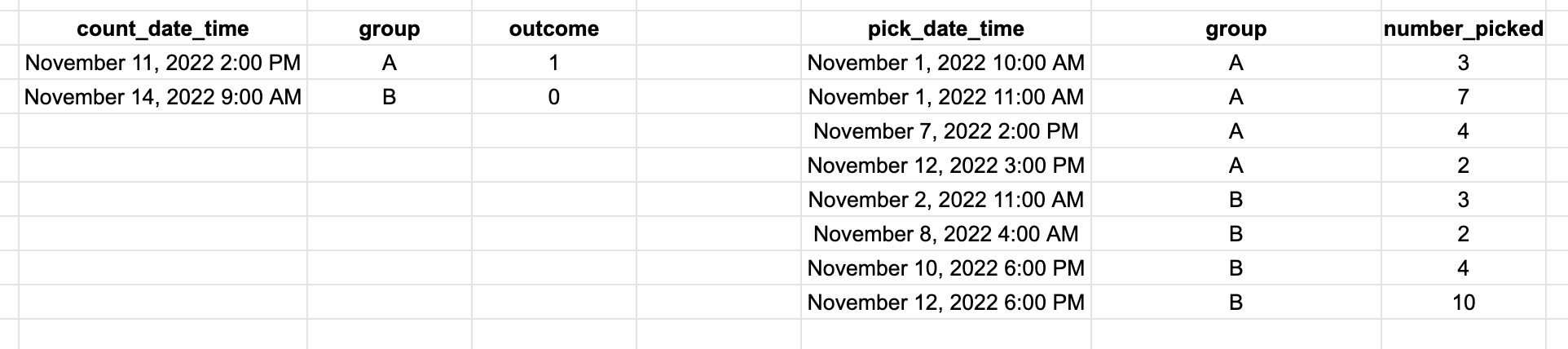
The result I want is for each row within the counts table (left side, 2 rows here) find the rolling 7 day sum prior or equal to this date of number_picked for the appropriate group. The first row is group A on November 11th, 2022 at 2pm so this would lookup all records in the pick table that are in group A and are on November 11, 2022 at 2pm - 7 days, then sum. This would be 4. For row 2 it would be group B, summing number_picked November 14th, 2022 at 9am - 7 days, which would be 16.
If I loop over each row and then do a temp table merge with the pick data, this will work but it's terrible practice to loop over rows in Python. In reality my count table is like 200k rows and the picks are millions. I cannot think of a smart way to do this that accomplishments handling the date gaps and is efficient.
Python code to reproduce below:
import pandas as pd
counts = pd.DataFrame(columns=['count_date_time', 'group', 'outcome'], data=[["November 11, 2022 2:00 PM",'A',1], ["November 14, 2022 9:00 AM",'B',0]])
counts['count_date_time'] = pd.to_datetime(counts['count_date_time'])
picks = pd.DataFrame(columns=['pick_date_time','group','number_picked'], data=[["November 1, 2022 10:00 AM","A",3],
["November 1, 2022 11:00 AM","A",7],
["November 7, 2022 2:00 PM","A",4],
["November 12, 2022 3:00 PM","A",2],
["November 2, 2022 11:00 AM","B",3],
["November 8, 2022 4:00 AM","B",2],
["November 10, 2022 6:00 PM","B",4],["November 12, 2022 6:00 PM","B",10]])
picks['pick_date_time'] = pd.to_datetime(picks['pick_date_time'])
CodePudding user response:
You can use numpy broadcasting to compare every row in counts to every row in picks. However, the resulting matrix will take n * m bytes, which may overwhelm your memory at the scale of your problem.
The solution below does it in chunks, so that it only needs chunk_size * m bytes of memory at a time. Larger chunk_size takes more memory but will probably run faster. Experiment to find a sweet spot:
chunk_size = 10_000
# Convert the relevant columns to numpy array
pick_date, pick_group, pick_number = picks.to_numpy().T
count_date, count_group = counts[["count_date_time", "group"]].to_numpy().T
# For the broadcasting, we need to raise these 2 arrays up one dimension
count_date = count_date[:, None]
count_group = count_group[:, None]
# The resulting total
total = np.zeros(len(counts))
for i in range(0, len(counts), chunk_size):
chunk = slice(i, i chunk_size)
# Compare a chunk of `counts` to every row in `picks`
to_dates = count_date[chunk]
from_dates = to_dates - pd.Timedelta(days=7)
groups = count_group[chunk]
mask = (from_dates <= pick_date) & (pick_date <= to_dates) & (groups == pick_group)
total[chunk] = (pick_number[None, :] * mask).sum(axis=1)
counts["total"] = total