I am loading a txt file containig complex number. The data are formatted in this way
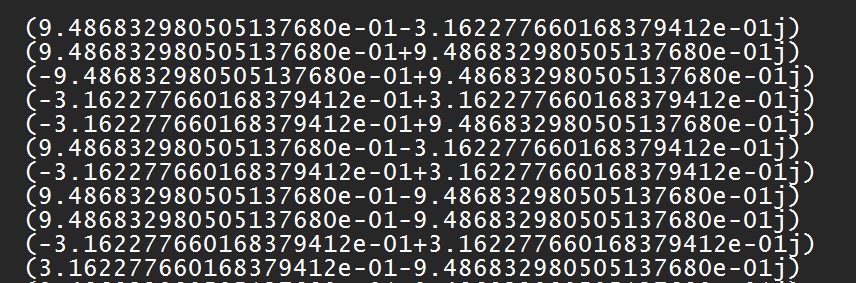
How can I create a two separate arrays, one for the real part and one for the immaginary part?
I tried to create a panda dataframe using e-01 as a separator but in this way I loose this info
CodePudding user response:
df = pd.read_fwf(r'c:\test\complex.txt', header=None)
df[['real','im']] = df[0].str.extract(r'\(([-.\de] )([ -]\d\.[\de\-j] )')
print(df)
0 real im
0 (9.486832980505137680e-01-3.162277660168379412... 9.486832980505137680e-01 -3.162277660168379412e-01j
1 (9.486832980505137680e-01 9.486832980505137680... 9.486832980505137680e-01 9.486832980505137680e-01j
2 (-9.486832980505137680e-01 9.48683298050513768... -9.486832980505137680e-01 9.486832980505137680e-01j
3 (-3.162277660168379412e-01 3.16227766016837941... -3.162277660168379412e-01 3.162277660168379412e-01j
4 (-3.162277660168379412e-01 9.48683298050513768... -3.162277660168379412e-01 9.486832980505137680e-01j
5 (9.486832980505137680e-01-3.162277660168379412... 9.486832980505137680e-01 -3.162277660168379412e-01j
6 (-3.162277660168379412e-01 3.16227766016837941... -3.162277660168379412e-01 3.162277660168379412e-01j
7 (9.486832980505137680e-01-9.486832980505137680... 9.486832980505137680e-01 -9.486832980505137680e-01j
8 (9.486832980505137680e-01-9.486832980505137680... 9.486832980505137680e-01 -9.486832980505137680e-01j
9 (-3.162277660168379412e-01 3.16227766016837941... -3.162277660168379412e-01 3.162277660168379412e-01j
10 (3.162277660168379412e-01-9.486832980505137680... 3.162277660168379412e-01 -9.486832980505137680e-01j
CodePudding user response:
Never knew how annoyingly involved it is to read complex numbers with Pandas, This is a slightly different solution than @Алексей's. I prefer to avoid regular expressions when not absolutely necessary.
# Read the file, pandas defaults to string type for contents
df = pd.read_csv('complex.txt', header=None, names=['string'])
# Convert string representation to complex.
# Use of `eval` is ugly but works.
df['complex'] = df['string'].map(eval)
# Alternatively...
#df['complex'] = df['string'].map(lambda c: complex(c.strip('()')))
# Separate real and imaginary parts
df['real'] = df['complex'].map(lambda c: c.real)
df['imag'] = df['complex'].map(lambda c: c.imag)
df
is...
string complex \
0 (9.486832980505137680e-01-3.162277660168379412... 0.948683-0.316228j
1 (9.486832980505137680e-01 9.486832980505137680... 0.948683 0.948683j
2 (-9.486832980505137680e-01 9.48683298050513768... -0.948683 0.000000j
3 (-3.162277660168379412e-01 3.16227766016837941... -0.316228 0.316228j
4 (-3.162277660168379412e-01 9.48683298050513768... -0.316228 0.948683j
5 (9.486832980505137680e-01-3.162277660168379412... 0.948683-0.316228j
6 (3.162277660168379412e-01 3.162277660168379412... 0.316228 0.316228j
7 (9.486832980505137680e-01-9.486832980505137680... 0.948683-0.948683j
real imag
0 0.948683 -3.162278e-01
1 0.948683 9.486833e-01
2 -0.948683 9.486833e-01
3 -0.316228 3.162278e-01
4 -0.316228 9.486833e-01
5 0.948683 -3.162278e-01
6 0.316228 3.162278e-01
7 0.948683 -9.486833e-01
df.dtypes
prints out..
string object
complex complex128
real float64
imag float64
dtype: object