The following code is from pg. 93 of 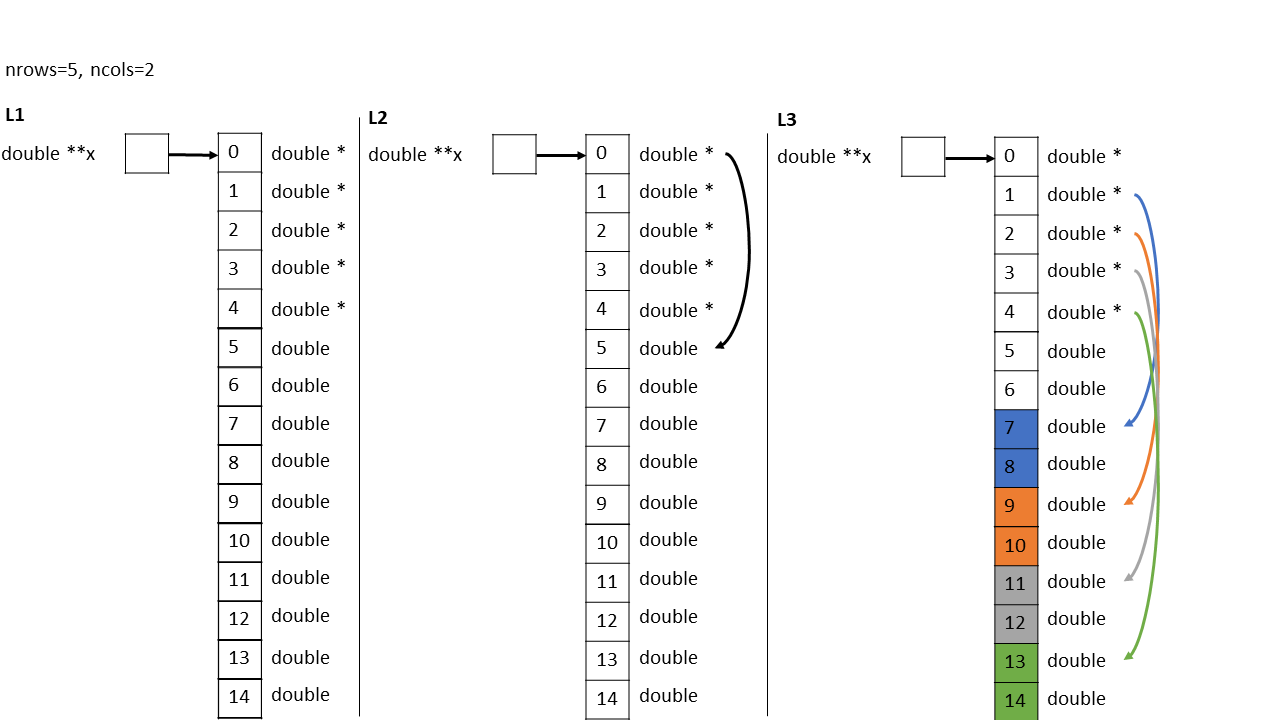
CodePudding user response:
The book states that this improves memory allocation and cache efficiency.
The book’s code improves efficiency relative to a too-often seen method of allocating pointers separately, as in:
double **x = malloc(nrows * sizeof *x);
for (size_t i = 0; i < nrows; i)
x[i] = malloc(ncols * sizeof *x[i]);
(Note that all methods should test the malloc result and handle allocation failures. This is elided for the discussion here.)
That method allocates each row separately (from other rows and from the pointers). The book’s method has some benefit that only one allocation is done and that the memory for the array is contiguous. Also, the relationships between elements in different rows are known, and that may allow programmers to take advantage of the relationships in designing algorithms that work well with cache and memory access.
Is there any reason w.r.t efficiency to prefer the first code to something like the below code?
Not for efficiency, no. Both the book’s method and the method above have the disadvantage that they generally require a pointer lookup for every array access (aside from the base pointer, x). Before the processor can get an element from the memory of a row, it has to get the address of the row from memory.
With the method you show, this additional lookup is unnecessary. Further, the processor and/or the compiler may be able to predict some things about the accesses. For example, with your method, the compiler may be able to see that M[(i 1)*ncols j] is a different element from M[(i 2)*cols j], whereas with x[i 1][j] and x[i 2][j], it generally cannot know the two pointers x[i 1] and x[i 2] are different.
The book’s code is also defective. The number of bytes it allocates is nrows*sizeof(double*) nrows*ncols*sizeof(double). Lets say r is nrows, c is ncols, p is sizeof(double*) and d is sizeof(double). Then the code allocates rp rcd bytes. Then the code sets x[0] to (double *)x nrows. Because it casts to double *, the addition of nrows is done in units of the pointed-to type, double. So this adds rd bytes to the starting address. And, after that, it expects to have all the elements of the array, which is rcd bytes. So the code is using rd rcd bytes even though it allocated rp rcd. If p > d, some elements at the end of the array will be outside of the allocated memory. In current ordinary C implementations, the size of double * is less than or equal to the size of double, but this should not be relied on. Instead of setting x[0] to (double *)x nrows;, it should calculate x plus the size of nrows elements of type double * plus enough padding to get to the alignment requirement of double, and it should include that padding in the allocation.
If we cannot use variable length arrays, then the array indexing can be provided by a macro, as by defining a macro that replaces x(i, j) with x[i*ncols j], such as #define x(i, j) x[(i)*ncols (j)].