I have a JSON file in the following format:
{ "first_name": "Jane", "last_name": "Doe", "userid": 12345, “profile”: { “annoying_field_name_10”: {“field_id”: 15, “field_name”: “Gender”, “value”: “Female”, “applicable”: 1 }, “annoying_field_name_11”: {“field_id”: 16, “field_name”: “Interests”, “value”: “Baking”, “applicable”: 1 } } }
In this file i have 5000 users, with around 150 profile fields each, the "annoying_field_name..." is completely unique for every user and field name combination. I would like to parse and flatten the file so my results look like this:
table

I have not been able to figure out how to use a wildcard or dynamics expressions in either parsing or flatten and unroll functions in ADF.
Is anyone able to advise further on this please?
I have tried using both the parse and flatten function in ADF, I have attempted to use the dynamic expressions in these but was unable to get this to run successfully. I have followed this question how to flatten multiple child nodes using jsonNodeReference in azure data factory and guide :https://adatis.co.uk/converting-json-with-nested-arrays-into-csv-in-azure-logic-apps-by-using-array-variable/ but the changing object name "annoying_field_name..." is proving restrictive.
CodePudding user response:
Flattening the nested JSON where key names are different is difficult to achieve in mapping dataflow as in dataflow, any transformation works on the defined source schema .
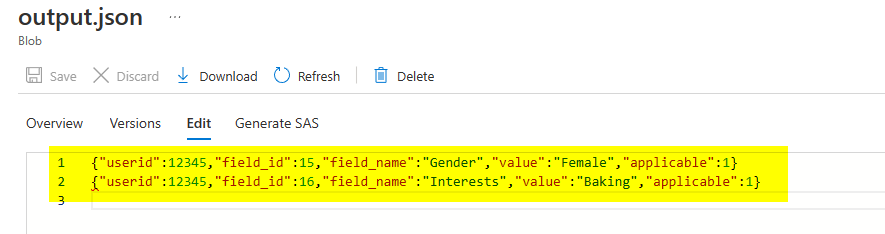
Either you can go for writing custom code in C#,JAVA and use custom activity in ADF or you can change the JSON to defined format like below and apply flatten transformation directly on top of it:
{
"first_name":"Jane",
"last_name":"Doe",
"userid":12345,
"profile":{
"annoying_field_name":[
{
"field_id":15,
"field_name":"Gender",
"value":"Female",
"applicable":1
},
{
"field_id":16,
"field_name":"Interests",
"value":"Baking",
"applicable":1
}
]
}
}
CodePudding user response:
I agree with @AnnuKumari-MSFT as in ADF we can only flatten the array of objects JSON.
I have tried to reproduce this, but Your JSON includes different keys so convert into array of objects like above.
Then, apart from flatten transformation in dataflow, you can also try copy activity to flatten.
Give the source and sink JSONs and Go to Mapping.
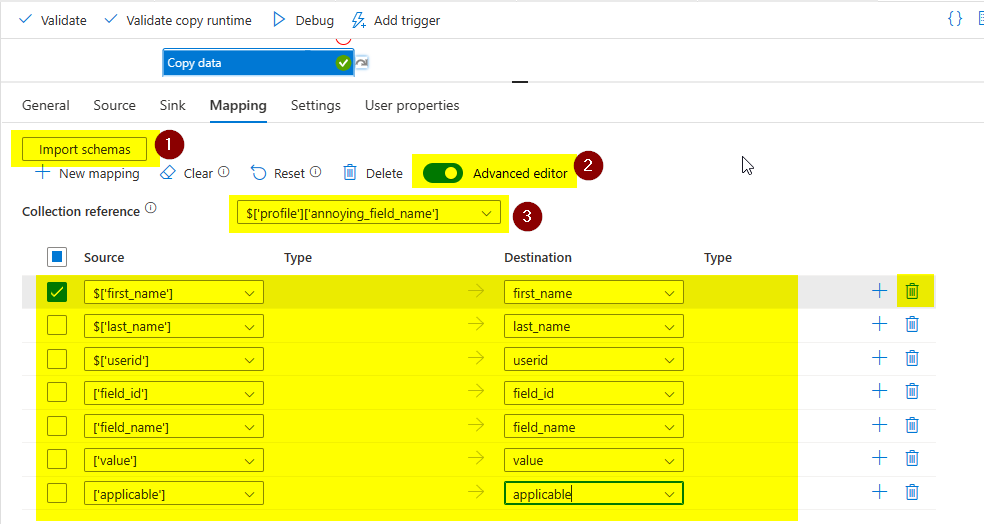
Give the respective names to the columns. you can delete the unwanted column like above.
Desired Result: