I have the following code which takes columns in my pandas df and calculates all combination of totals minus duplicates:
import itertools as it
import pandas as pd
df = pd.DataFrame({'a': [3,4,5,6,3], 'b': [5,7,1,0,5], 'c':[3,4,2,1,3], 'd':[2,0,1,5,9]})
orig_cols = df.columns
for r in range(2, df.shape[1] 1):
for cols in it.combinations(orig_cols, r):
df["_".join(cols)] = df.loc[:, cols].sum(axis=1)
df
Which generates the desired df:
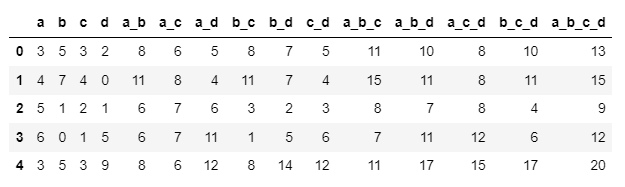
To take advantage of distributed computing I want to run this same code but using pyspark.pandas. I convert the df to spark and apply the same code....
import itertools as it
import pandas as pd
import pyspark.pandas as ps
df = pd.DataFrame({'a': [3,4,5,6,3], 'b': [5,7,1,0,5], 'c':[3,4,2,1,3], 'd':[2,0,1,5,9]})
dfs = ps.from_pandas(df) # convert from pandas to pyspark
orig_cols = dfs.columns
for r in range(2, dfs.shape[1] 1):
for cols in it.combinations(orig_cols, r):
dfs["_".join(cols)] = dfs.loc[:, cols].sum(axis=1)
dfs
but I am getting an error message:
IndexError: tuple index out of range
Why is the code not working? What change do I need to make so it can work in pyspark?
CodePudding user response:
The error fixed by converting tuple to list. Try this:
import itertools as it
import pandas as pd
import pyspark.pandas as ps
ps.set_option('compute.ops_on_diff_frames', True)
df = pd.DataFrame({'a': [3,4,5,6,3], 'b': [5,7,1,0,5], 'c':[3,4,2,1,3], 'd':[2,0,1,5,9]})
dfs = ps.from_pandas(df) # convert from pandas to pyspark
orig_cols = dfs.columns
for r in range(2, dfs.shape[1] 1):
for cols in it.combinations(orig_cols, r):
dfs["_".join(list(cols))] = dfs.loc[:, list(cols)].sum(axis=1)
dfs