Some details are as follows:
- NebulaGraph version is 3.3.0
- NebulaGraph Studio version is 3.5.0
- Deployment way is distributed
Data volume is as following:
The nodes are Comment, and the edges are the ones in the red box.
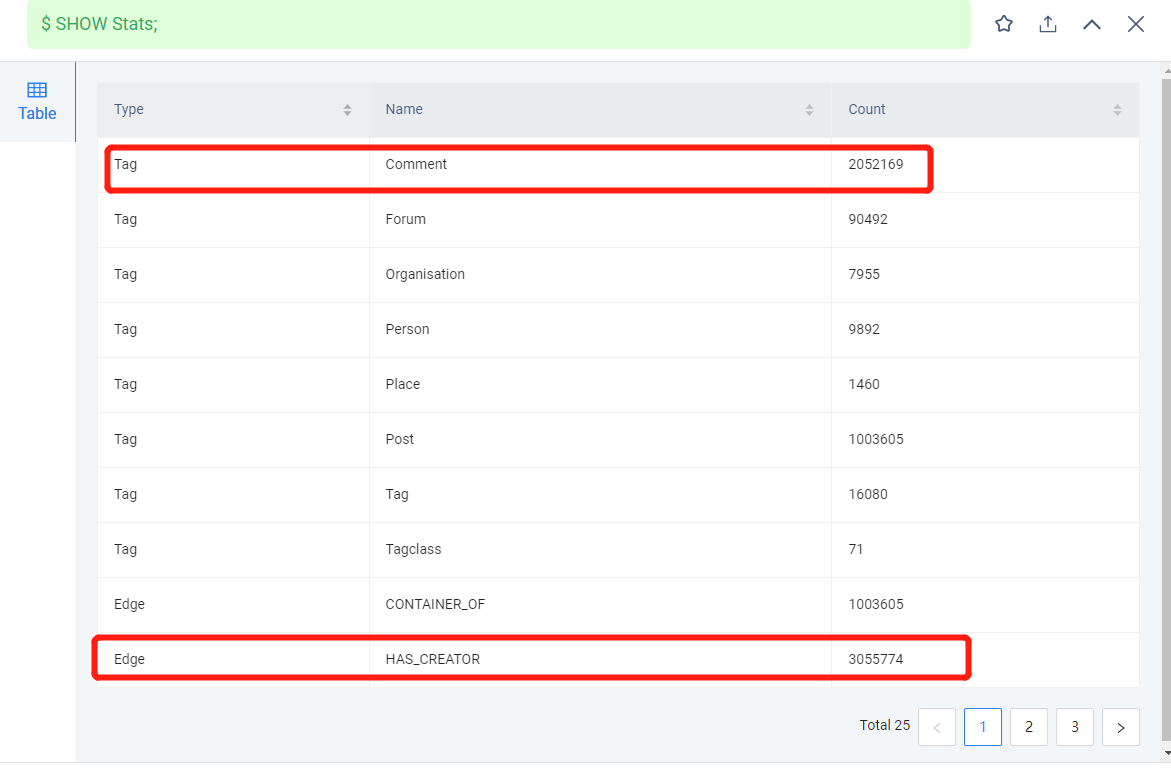
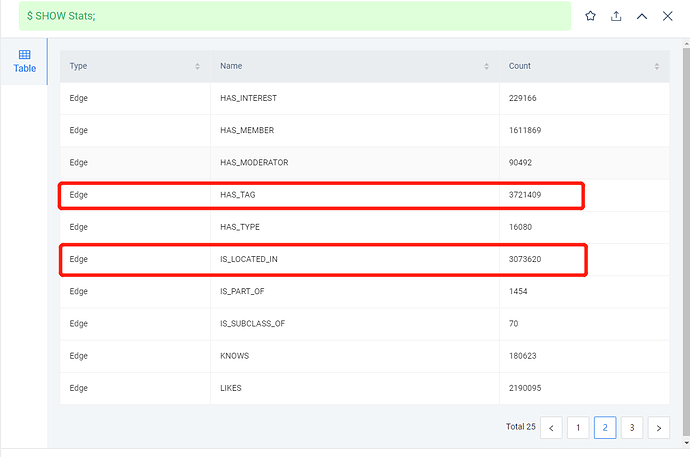
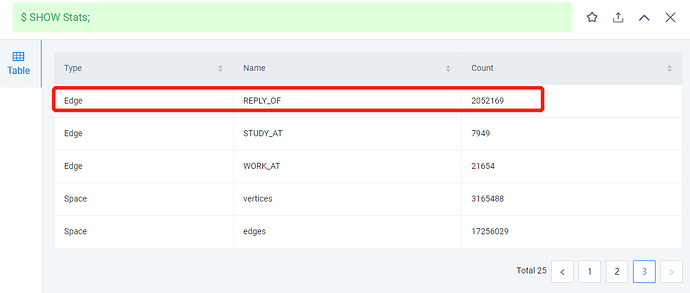
application.conf:
{
# Spark relation config
spark: {
app: {
name: louvain
# spark.app.partitionNum
partitionNum:50
}
master:local
}
data: {
# data source. optional of nebula,csv,json
source: nebula
# data sink, means the algorithm result will be write into this sink. optional of nebula,csv,text
sink: nebula
# if your algorithm needs weight
hasWeight: false
}
# Nebula Graph relation config
nebula: {
# algo's data source from Nebula. If data.source is nebula, then this nebula.read config can be valid.
read: {
# Nebula metad server address, multiple addresses are split by English comma
metaAddress: "192.168.200.100:9559,192.168.200.101:9559,192.168.200.111:9559"
# Nebula space
space: ldbc
# Nebula edge types, multiple labels means that data from multiple edges will union together
labels: ["HAS_CREATOR","HAS_TAG","IS_LOCATED_IN","REPLY_OF"]
# Nebula edge property name for each edge type, this property will be as weight col for algorithm.
# Make sure the weightCols are corresponding to labels.
weightCols: [""]
}
# algo result sink into Nebula. If data.sink is nebula, then this nebula.write config can be valid.
write:{
# Nebula graphd server address, multiple addresses are split by English comma
graphAddress: "192.168.200.100:9669,192.168.200.101:9669,192.168.200.111:9669,192.168.200.112:9669,192.168.200.114:9669"
# Nebula metad server address, multiple addresses are split by English comma
metaAddress: "192.168.200.100:9559,192.168.200.101:9559,192.168.200.111:9559"
user:root
pswd:nebula
# Nebula space name
space:ldbc
# Nebula tag name, the algorithm result will be write into this tag
tag:Comment
# algorithm result is insert into new tag or update to original tag. type: insert/update
type:update
}
}
local: {
# algo's data source from Nebula. If data.source is csv or json, then this local.read can be valid.
read:{
filePath: "file:///tmp/edge_follow.csv"
# srcId column
srcId:"_c0"
# dstId column
dstId:"_c1"
# weight column
#weight: "col3"
# if csv file has header
header: false
# csv file's delimiter
delimiter:","
}
# algo result sink into local file. If data.sink is csv or text, then this local.write can be valid.
write:{
resultPath:/tmp/count
}
}
algorithm: {
# the algorithm that you are going to execute,pick one from [pagerank, louvain, connectedcomponent,
# labelpropagation, shortestpaths, degreestatic, kcore, stronglyconnectedcomponent, trianglecount,
# betweenness, graphtriangleCount, clusteringcoefficient, bfs, hanp, closeness, jaccard, node2vec]
executeAlgo: louvain
# PageRank parameter
pagerank: {
maxIter: 10
resetProb: 0.15 # default 0.15
}
# Louvain parameter
louvain: {
maxIter: 20
internalIter: 10
tol: 0.5
}
# connected component parameter.
connectedcomponent: {
maxIter: 20
}
# LabelPropagation parameter
labelpropagation: {
maxIter: 20
}
# ShortestPaths parameter
shortestpaths: {
# several vertices to compute the shortest path to all vertices.
landmarks: "1"
}
# Vertex degree statistics parameter
degreestatic: {}
# KCore parameter
kcore:{
maxIter:10
degree:1
}
# Trianglecount parameter
trianglecount:{}
# graphTriangleCount parameter
graphtrianglecount:{}
# Betweenness centrality parameter. maxIter parameter means the max times of iterations.
betweenness:{
maxIter:5
}
# Clustering Coefficient parameter. The type parameter has two choice, local or global
# local type will compute the clustering coefficient for each vertex, and print the average coefficient for graph.
# global type just compute the graph's clustering coefficient.
clusteringcoefficient:{
type: local
}
# ClosenessAlgo parameter
closeness:{}
# BFS parameter
bfs:{
maxIter:5
root:"10"
}
# HanpAlgo parameter
hanp:{
hopAttenuation:0.1
maxIter:10
preference:1.0
}
#Node2vecAlgo parameter
node2vec:{
maxIter: 10,
lr: 0.025,
dataNumPartition: 10,
modelNumPartition: 10,
dim: 10,
window: 3,
walkLength: 5,
numWalks: 3,
p: 1.0,
q: 1.0,
directed: false,
degree: 30,
embSeparate: ",",
modelPath: "hdfs://127.0.0.1:9000/model"
}
# JaccardAlgo parameter
jaccard:{
tol: 1.0
}
}
}
When I execute spark-submit --master "local" --class com.vesoft.nebula.algorithm.Main /opt/offline/nebula/nebula-algorithm-3.0.0.jar -p /opt/offline/nebula/application.conf, it reports the error in the screenshot.
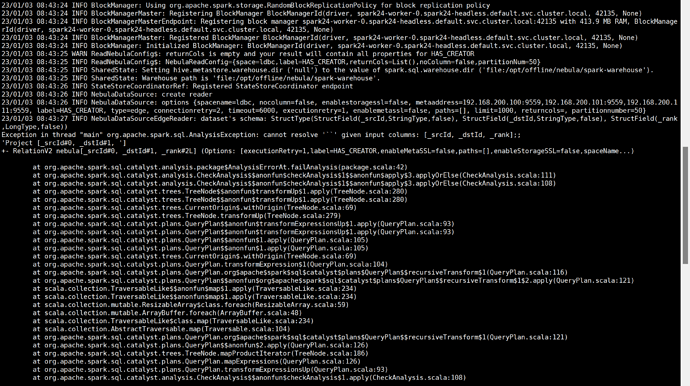
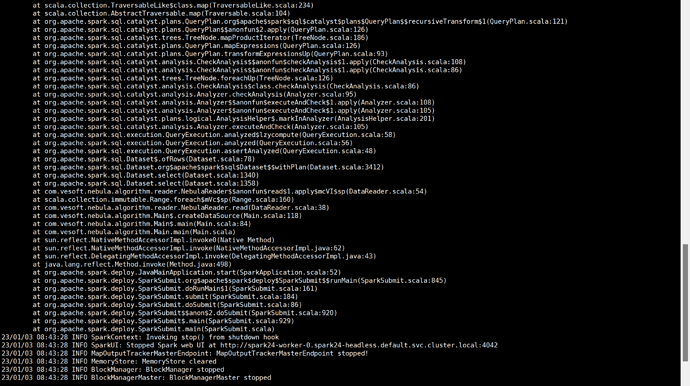
How should I solve this error?
CodePudding user response:
Check the appliation.conf. If the item weightcols is empty, use [""] without and blank.
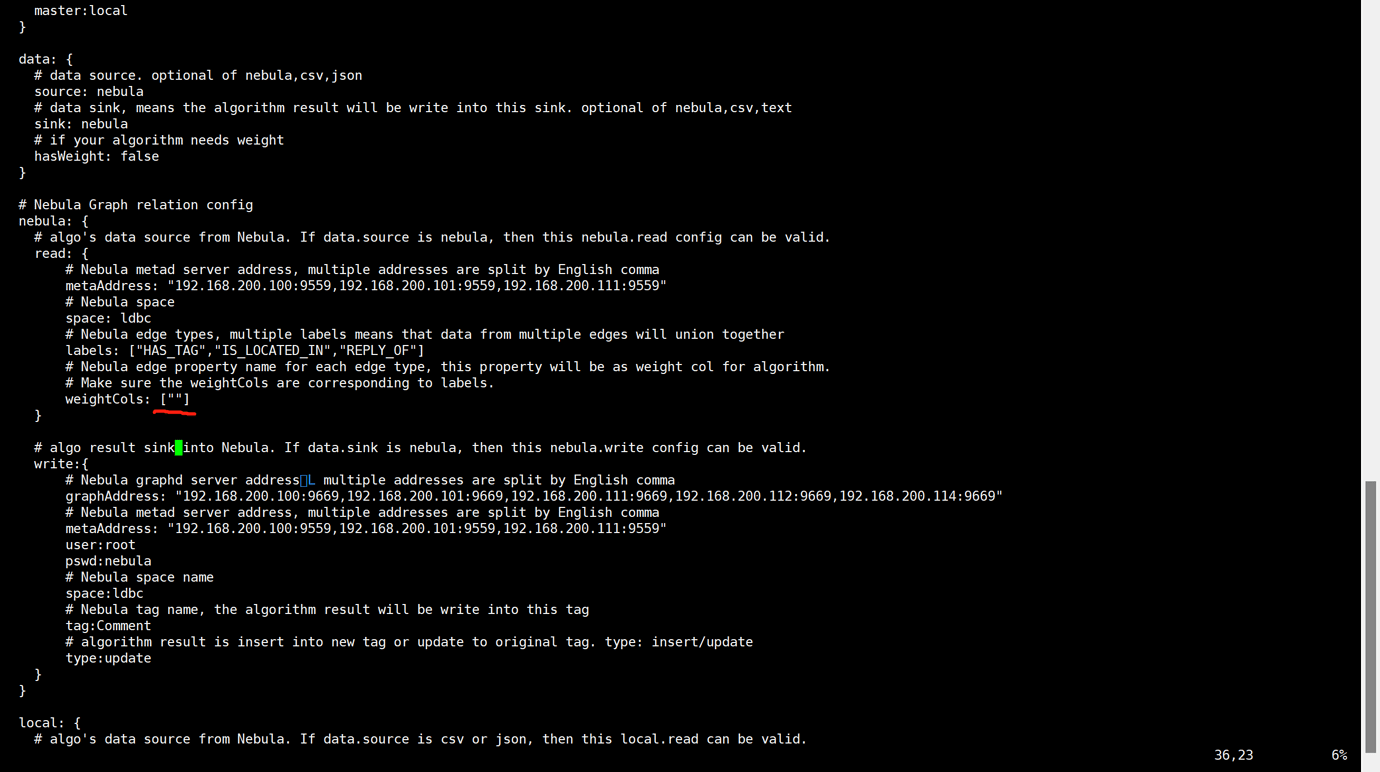
CodePudding user response:
The value of the weightcols parameter in the application.conf file cannot be quoted if it is empty.