Let's say I have data below
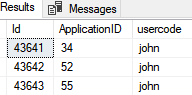
How can I display this data side by side with lowest id and so on without UNION?
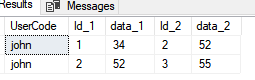
I'm thinking about giving sequence number for every data that has the same usercode, create table temporary for each iteration, and then join them.
Here the code
DROP TABLE #TEMP
CREATE TABLE #TEMP (
ID INT,
[data] INT,
usercode NVARCHAR(50),
RowNum INT
)
INSERT INTO #TEMP(ID, [data], UserCode, RowNum)
SELECT Id, ApplicationID, 'john', ROW_NUMBER() OVER (ORDER BY Usercode) RNum from UserApplicationAccess
This is inserted data, so I'm giving a sequence number for each row for mark every data with id
select a.UserCode, a.RowNum Id_1, a.[data] data_1, b.RowNum Id_2, b.[data] data_2 from #TEMP a join #TEMP b on a.UserCode = b.UserCode
where a.RowNum = 1 and b.RowNum = 2
union
select a.UserCode, a.RowNum Id_1, a.[data] data_1, b.RowNum Id_2, b.[data] data_2 from #TEMP a join #TEMP b on a.UserCode = b.UserCode
where a.RowNum = 2 and b.RowNum = 3
This is how I query to get the data that I want, it works but since there is no limitation how many data for every user, I think this query is not enough. For example this data just have 3 row, so I'm using union just twice, but there are user that have 10 data, so I have to write 9 union, and so on, and so on.
CodePudding user response:
It looks like you're trying to convert adjacent rows into a range, so if for each usercode you have 10 rows, you want to produce 9 output rows, each with the current and "next" ApplicationID value. You can do that using the LEAD or LAG functions.
Given this data:
declare @TEMP table(
ID INT,
ApplicationId INT,
usercode NVARCHAR(50)
)
insert into @temp (ID,ApplicationId,usercode)
values
(43461,34,'john'),
(43462,52,'john'),
(43463,55,'john');
The following query will produce the desired result:
with a as(
SELECT usercode,
row_number() over (partition by usercode order by id) as RN,
applicationid,
lag(applicationid) over (partition by usercode order by id) as Prev
from @temp)
SELECT
usercode,
rn-1 as ID_1 ,
prev as data_1,
rn as ID_2,
applicationid as data_2
from a
where prev is not null
This returns
usercode ID_1 data_1 ID_2 data_2
john 1 34 2 52
john 2 52 3 55
over (partition by usercode order by id) partitions the data by usercode and orders it by ID. After that, we can calculate the row number in the partition and retrieve the previous or next value using LAG or LEAD.
LAG/LEAD will return NULL at the edges, so prev is not null is used to exclude the edge pair.
CodePudding user response:
Since what you are trying to do is get n-1 rows for each usercode, you can use LEAD() to get the next value and omit when this is null (i.e. the last row). The exception to this would be if there is only one row for a user, which you can avoid by always including the first row for every user. So you would end up with something like this:
WITH YourData AS
( SELECT ID, ApplicationID, UserCode
FROM (VALUES
(43641, 34, 'John'),(43642, 52, 'John'),(43643, 55, 'John'), (43648, 55, 'Bill'),
(43645, 34, 'Steve'),(43646, 52, 'Steve'),(43647, 55, 'Steve'),(43648, 56, 'Steve')
) AS d (ID, ApplicationID, UserCode)
)
SELECT d.UserCode,
ID_1 = d.RowNumber,
Data_1 = d.ApplicationID,
ID_2 = CASE WHEN d.NextApplicationID IS NULL THEN NULL ELSE d.RowNumber 1 END,
Data_2 = d.NextApplicationID
FROM ( SELECT d.ID,
d.ApplicationID,
d.UserCode,
RowNumber = ROW_NUMBER() OVER(PARTITION BY d.UserCode ORDER BY d.ApplicationID),
NextApplicationID = LEAD(d.ApplicationID) OVER(PARTITION BY d.UserCode ORDER BY d.ApplicationID)
FROM YourData AS d
) AS d
WHERE d.NextApplicationID IS NOT NULL
OR d.RowNumber = 1;
Which gives:
| UserCode | ID_1 | Data_1 | ID_2 | Data_2 |
|---|---|---|---|---|
| Bill | 1 | 55 | NULL | NULL |
| John | 1 | 34 | 2 | 52 |
| John | 2 | 52 | 3 | 55 |
| Steve | 1 | 34 | 2 | 52 |
| Steve | 2 | 52 | 3 | 55 |
| Steve | 3 | 55 | 4 | 56 |
CodePudding user response:
Looks straightforward enough, unless I've overlooked something.
You want to show the rows ordered by their id - probably within the same user code , and then the application id, some sequence number, the application id of the succeeding row, and the sequence number incremented by 1. And you don't want to show rows that have no successor, within the same usercode .
WITH
indata(id,appid,usercode) AS (
SELECT 43461,34,'john'
UNION ALL SELECT 43462,52,'john'
UNION ALL SELECT 43463,55,'john'
)
,
olap AS (
SELECT
usercode
, ROW_NUMBER() OVER(PARTITION BY usercode ORDER BY id) AS id_1
, appid AS data_1
, ROW_NUMBER() OVER(PARTITION BY usercode ORDER BY id) 1 AS id_2
, LEAD(appid) OVER(PARTITION BY usercode ORDER BY id) AS data_2
FROM indata
)
SELECT
*
FROM olap
WHERE data_2 IS NOT NULL;
-- out usercode | id_1 | data_1 | id_2 | data_2
-- out ---------- ------ -------- ------ --------
-- out john | 1 | 34 | 2 | 52
-- out john | 2 | 52 | 3 | 55