I am trying to transform a hierarchy that use a columnar format with a fixed number of columns (many of them being null) into an adjacency list, with child and parent, using the Pandas library.
example hierarchy
Here is a fictitious example with 5 hierarchical levels:
Books
/ | \
Science (null) (null)
/ | \
Astronomy (null) Pictures
/ \ | \
Astrophysics Cosmology (null) Astronomy
/ \ | / | \
(null) (null) Amateurs_Astronomy Galaxies Stars Astronauts
data.csv
id,level_1,level_2,level_3,level_4,level_5
1,Books,Science,Astronomy,Astrophysics,
2,Books,Science,Astronomy,Cosmology,
3,Books,,,,Amateurs_Astronomy
4,Books,,Pictures,Astronomy,Galaxies
5,Books,,Pictures,Astronomy,Stars
6,Books,,Pictures,Astronomy,Astronauts
what I have done
I have started by adding a column that will store a uuid for each existing node.
[EDIT, further to mozway comment]
The problem with this function is that it will populate different uuids for nodes which are the same:
- first and second rows have the same level 1, 2, 3 and so should have the same uuid as pk_level_3
- in the same way, rows 4, 5 and 6 should have the same uuid as pk_level_3 and pk_level_4.
import pandas as pd
df = pd.read_csv('data.csv')
# iterate over each column in the dataframe to add a new column,
# containing a uuid each time the csv row has a value for this level:
for col in df.columns:
if df[col].isnull().sum() > 0:
new_col = 'pk_' col
df[new_col] = None
# fill the new column with uuid only for non-null values of the original column
df.loc[df[col].notnull(), new_col] = df.loc[df[col].notnull(), col].apply(lambda x: uuid.uuid4())
Also, I do not know how to find the parent for each node, skipping all the null ones.
Any idea on how I could get the following result ?
this_node,parent_node,this_node_uuid,parent_node_uuid
Science,Books,books/science-node-uuid,books-node-uuid
Astronomy,Science,books/science/astronomy-node-uuid,books/science-node-uuid
Astrophysics,Astronomy,books/science/astronomy/astrophysics-node-uuid,books/science/astronomy-node-uuid
Amateurs_Astronomy,Books,books/amateurs_astronomy-node-uuid,books-node-uuid
(…)
CodePudding user response:
Here is one approach to generate the uuid per value and level, then the adjacency list:
import uuid
from collections import defaultdict
mapper = defaultdict(uuid.uuid4)
df2 = (df.stack().reset_index(name='node')
.assign(uuid=lambda d: d.groupby(['level_1', 'node']).ngroup().map(mapper))
)
(df2[['node', 'uuid']]
.join(df2.groupby('id')[['node', 'uuid']].shift(-1).add_prefix('parent_'))
.dropna()
[['node', 'parent_node', 'uuid', 'parent_uuid']]
)
Output:
node parent_node uuid parent_uuid
0 Books Science 73299f14-db0b-49ac-8050-13ba909fbbf9 d5eabe29-9822-4cd5-832f-e7a69630ed1a
1 Science Astronomy d5eabe29-9822-4cd5-832f-e7a69630ed1a f72718d8-99d0-4160-ab2b-c4d990c103bc
2 Astronomy Astrophysics f72718d8-99d0-4160-ab2b-c4d990c103bc 03f6af50-df0f-4762-8791-3c06103dae62
4 Books Science 73299f14-db0b-49ac-8050-13ba909fbbf9 d5eabe29-9822-4cd5-832f-e7a69630ed1a
5 Science Astronomy d5eabe29-9822-4cd5-832f-e7a69630ed1a f72718d8-99d0-4160-ab2b-c4d990c103bc
6 Astronomy Cosmology f72718d8-99d0-4160-ab2b-c4d990c103bc 27de8aa5-5805-41f0-b127-e1c962328398
8 Books Amateurs_Astronomy 73299f14-db0b-49ac-8050-13ba909fbbf9 af5763c3-9f55-4815-88c8-3996bd2407db
10 Books Pictures 73299f14-db0b-49ac-8050-13ba909fbbf9 7cbc093c-b34c-4d45-8e38-24cc68b6ccc5
11 Pictures Astronomy 7cbc093c-b34c-4d45-8e38-24cc68b6ccc5 41bf967b-d6ca-4da7-b5ad-3ec05ceefd43
12 Astronomy Galaxies 41bf967b-d6ca-4da7-b5ad-3ec05ceefd43 68a8cb4f-def5-492d-b497-318a074a1f15
14 Books Pictures 73299f14-db0b-49ac-8050-13ba909fbbf9 7cbc093c-b34c-4d45-8e38-24cc68b6ccc5
15 Pictures Astronomy 7cbc093c-b34c-4d45-8e38-24cc68b6ccc5 41bf967b-d6ca-4da7-b5ad-3ec05ceefd43
16 Astronomy Stars 41bf967b-d6ca-4da7-b5ad-3ec05ceefd43 9d823bdd-fd3e-43a3-8756-51160490c8ed
18 Books Pictures 73299f14-db0b-49ac-8050-13ba909fbbf9 7cbc093c-b34c-4d45-8e38-24cc68b6ccc5
19 Pictures Astronomy 7cbc093c-b34c-4d45-8e38-24cc68b6ccc5 41bf967b-d6ca-4da7-b5ad-3ec05ceefd43
20 Astronomy Astronauts 41bf967b-d6ca-4da7-b5ad-3ec05ceefd43 609e708f-60cd-4928-863c-d41255330981
graph
import networkx as nx
G = nx.from_pandas_edgelist(out, source='uuid', target='parent_uuid', create_using=nx.DiGraph)
nx.set_node_attributes(G, {k: v for (_, v), k in mapper.items()}, name='label')
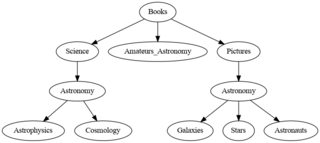
CodePudding user response:
From here, how do you generate your uuids?
def build_hierarchy(df):
return pd.concat([df.shift(-1), df], keys=['node', 'parent'], axis=1)
out = (df.set_index('id').stack()
.groupby(level='id', group_keys=False).apply(build_hierarchy)
.droplevel(1).reset_index())
Output:
>>> out
id node parent
0 1 Science Books
1 1 Astronomy Science
2 1 Astrophysics Astronomy
3 1 None Astrophysics
4 2 Science Books
5 2 Astronomy Science
6 2 Cosmology Astronomy
7 2 None Cosmology
8 3 Amateurs_Astronomy Books
9 3 None Amateurs_Astronomy
10 4 Pictures Books
11 4 Astronomy Pictures
12 4 Galaxies Astronomy
13 4 None Galaxies
14 5 Pictures Books
15 5 Astronomy Pictures
16 5 Stars Astronomy
17 5 None Stars
18 6 Pictures Books
19 6 Astronomy Pictures
20 6 Astronauts Astronomy
21 6 None Astronauts