I have some data in a dict that I would like to save as an csv file with pandas:
data = {
"a": 1,
"c": 2,
"d": 3,
}
Which I am trying to save it in this format:

I am doing this with:
data = pd.DataFrame(data, index=[0])
data.to_csv(path, mode='a', columns=None, header=list(data.keys()))
After data is saved, I will have more entries (dict) that are in the same format as data that I need to append to the same csv file. Let's suppose I have:
data2 = {
"a": 2,
"c": 3,
"d": 4,
}
I need to append it as this:

But if I ran the same code with data2, the headers will be displayed again:
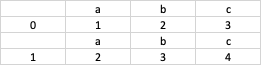
Is there a way to automatically add the header if it is the first entry, and for subsequent entries, no header will be added with the same code. I cannot detect in my code which data is the first entry.
CodePudding user response:
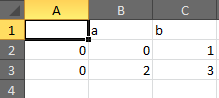
Only add the headers if the file does not exist:
import pandas
import os
data = pd.DataFrame({'a': [0], 'b': [1]})
data2 = pd.DataFrame({'a': [2], 'b': [3]})
path = './data.csv'
data.to_csv(path, mode='a', header=not os.path.exists(path))
data2.to_csv(path, mode='a', header=not os.path.exists(path))
CodePudding user response:
Use header=None after the first export:
data = pd.DataFrame(data, index=[0])
data.to_csv(path, mode='a')
data2 = pd.DataFrame(data2, index=[0])
data2.to_csv(path, mode='a', header=None)
Output:
,a,c,d
0,1,2,3
0,2,3,4
CodePudding user response:
To append new data without header just try to set header=False for next rows